
Por que backup em cloud hoje é questão de sobrevivência
Quando você ouve “backups e recuperação de desastres em cloud”, parece algo distante até o dia em que um ransomware paralisa o faturamento ou uma falha humana apaga um banco de produção. Em ambientes modernos, não basta ter cópias de dados: é preciso desenhar estratégias de backup e recuperação de desastres que considerem ataques avançados, outages de regiões inteiras e erros de configuração em larga escala. Cloud facilita muita coisa, mas também amplifica riscos, porque um único script mal feito pode comprometer tudo em segundos.
Real cases: quando o backup existe, mas não salva
Um varejista digital migrado para backup em nuvem empresarial achava que estava protegido: snapshots diários, retenção de 30 dias, tudo automatizado. Quando veio o ransomware, descobriram que os snapshots estavam na mesma conta, mesmas credenciais e mesma região que o ambiente produtivo. O atacante, com acesso privilegiado, deletou produção e backup em minutos. Moral da história: ter cópia não é suficiente; é preciso isolamento lógico, políticas imutáveis e teste frequente de restauração, senão o “plano” é apenas documentação bonita.
Três abordagens clássicas: cold, warm e hot standby
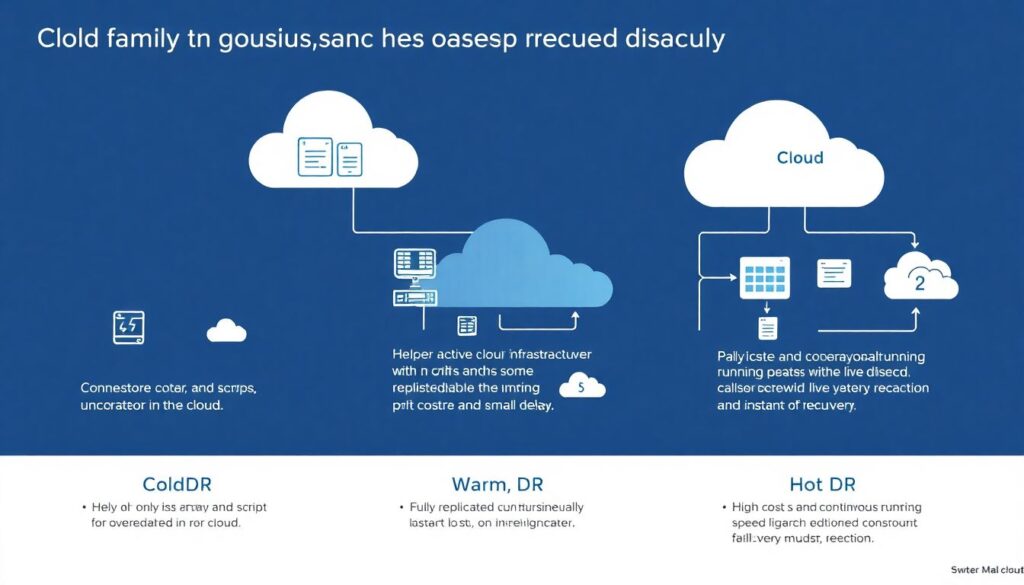
Se simplificar, existem três grandes famílias de soluções de disaster recovery em cloud.
1) Cold: você só armazena dados e scripts, ativa recursos apenas em desastre; é barato, mas com RTO alto.
2) Warm: mantém infraestrutura parcial ligada, sincronizando dados com atraso pequeno.
3) Hot: tudo replicado quase em tempo real, pronto para assumir tráfego. Conversando com equipes de finanças, saúde ou e‑commerce, a escolha gira em torno de quanto tempo e quantos dados podem ser perdidos na prática, não no papel.
Comparando RPO, RTO e a dor de pagar a conta
Cold standby costuma ser o favorito de quem tem budget apertado, mas aceita ficar algumas horas ou até um dia offline. Warm standby equilibra custo e rapidez, usando replicação assíncrona, autoscaling e scripts de promoção de bancos. Já hot standby é o sonho de muita área de negócio, com RPO próximo de zero, mas a fatura de infraestrutura extra assusta. O truque é conversar com stakeholders, traduzindo “cinco minutos de RPO” em perda de transações, multas regulatórias e impacto em reputação, antes de assinar o cheque.
Não óbvios: backups imutáveis, air-gap lógico e contas sacrificiais
Uma camada pouco discutida é o uso de storage imutável e air-gap lógico. Em vez de só guardar cópias, você configura políticas WORM (write once, read many) para que nem administradores possam apagar versões críticas antes do prazo. Outro recurso é usar contas “sacrificiais” e até outro provedor apenas para o cofre de backup. Isso quebra a cadeia de ataque: mesmo que o invasor comprometa produção, os serviços de backup em nuvem para empresas ficam fora de alcance direto, exigindo um esforço bem maior para destruição total.
Alternativas híbridas: multi‑cloud, on‑prem e edge
Nem todo mundo quer ou pode apostar tudo em um único hyperscaler. Muita empresa monta um plano de recuperação de desastres em nuvem usando combinação de data center próprio, segunda região de cloud e às vezes um segundo provedor. Dá mais trabalho de orquestrar, mas reduz risco de vendor lock‑in e falhas catastróficas de um único player. Outra alternativa é gravar restaurações críticas em armazenamento de objeto em outra nuvem, criptografado, como última linha de defesa caso a conta principal seja comprometida ou bloqueada por engano.
Lifehacks de profissionais que suaram em DR drills

Engenheiros que já passaram por incidentes reais costumam ter alguns hábitos bem pragmáticos. Primeiro, tratam DR como código: toda a infraestrutura de recuperação é descrita em IaC, versionada e testada em pipelines. Segundo, mantêm playbooks de “restauração de um clique”, com runbooks automatizados e checagens de integridade. Terceiro, testam cenários desagradáveis: recuperação sem acesso ao console principal, sem DNS primário ou com metade da equipe indisponível. Sem esse nível de paranoia organizada, as melhores estratégias de backup e recuperação de desastres ficam só no slide.
Checklist mínimo para um desenho resiliente
Para fechar, um framework direto para qualquer time que pensa em backup em nuvem empresarial de forma séria:
1) Definir RPO/RTO realistas com o negócio.
2) Garantir cópias imutáveis e isoladas em outra conta ou provedor.
3) Automar restauração com IaC e scripts idempotentes.
4) Validar segurança: chaves, acessos, rotação, logs.
5) Rodar testes regulares de failover e retorno.
6) Revisar o desenho após cada incidente ou mudança estrutural. Assim, soluções de disaster recovery em cloud deixam de ser promessa e viram prática diária.