
Por que a nuvem virou o centro da estratégia de backup e continuidade em 2026
Em 2026, pensar em backup e recuperação de desastres como algo “secundário” é praticamente um convite a ficar fora do ar depois de um incidente sério. Ataques de ransomware cada vez mais sofisticados, falhas em cadeias de supply chain de software, dependência massiva de APIs de terceiros e uso intenso de SaaS mudaram o jogo. A nuvem deixou de ser apenas um lugar barato para guardar cópias e virou a espinha dorsal da resiliência digital. Quando falamos em estratégia de backup na nuvem para empresas hoje, estamos falando de combinar automação, imutabilidade, criptografia forte, observabilidade em tempo quase real e testes frequentes de restauração, com políticas que tratam dados em múltiplas camadas: bancos de dados críticos, aplicações containerizadas, workloads de IA e até dispositivos de borda.
Outra grande mudança é que backup e continuidade de negócio não são mais projetos isolados de TI; são elementos centrais da governança corporativa, revisados em comitês de risco e alinhados a frameworks como ISO 22301, ISO 27001 e NIST. Além disso, fornecedores de cloud e de segurança agora oferecem serviços integrados com detecção de anomalias baseada em machine learning, que identificam padrões típicos de criptografia maliciosa e acionam políticas de bloqueio automático. Nesse cenário, montar um plano de recuperação de desastres em cloud computing sem considerar automação, multi-região e integração com ferramentas de segurança é ficar preso em uma mentalidade de 2015, que simplesmente não acompanha o nível de exposição e as exigências regulatórias atuais.
Passo 1: Entender o que realmente precisa sobreviver a um desastre
Antes de abrir o console da nuvem ou contratar novos serviços, o primeiro passo é mapear o que é crítico para o negócio. Não adianta falar em soluções de continuidade de negócios na nuvem se ninguém definiu quais processos precisam voltar primeiro, qual o impacto financeiro de cada hora parado e quanto de perda de dados é aceitável. Aqui entram conceitos como RTO (Recovery Time Objective) e RPO (Recovery Point Objective). Em linguagem direta: quanto tempo você aguenta ficar fora do ar e de quantos minutos ou horas de dados você aceita abrir mão em um cenário extremo. Para sistemas de pagamento, o RPO quase sempre é de minutos ou até segundos; para relatórios históricos, talvez algumas horas sejam aceitáveis, o que muda completamente a arquitetura de backup.
Esse mapeamento não deve ficar restrito ao CIO ou à equipe de infraestrutura; envolver áreas como financeiro, operações, jurídico e compliance é crucial para que as prioridades reflitam a realidade do negócio e as obrigações legais. Uma armadilha comum, especialmente para iniciantes, é confundir importância técnica com criticidade de negócio, gastando energia demais com sistemas que podem ficar horas indisponíveis e negligenciando integrações menos visíveis, mas que travam o faturamento se caírem. Em 2026, com ambientes cada vez mais distribuídos — microserviços, APIs de terceiros, plataformas de IA, IoT — entender dependências entre componentes antes de desenhar backups é o que diferencia um plano robusto de um documento bonito que não funciona na prática.
Passo 2: Desenhar a arquitetura de backup em camadas
Depois de saber o que precisa ser protegido, o próximo passo é estruturar uma estratégia de backup na nuvem para empresas em camadas, pensando em diferentes níveis de reação. A primeira camada é a de proteção operacional: snapshots frequentes de bancos de dados, backups consistentes de VMs e clusters Kubernetes, replicação contínua de dados críticos para outra zona ou região, além de logs detalhados armazenados em camadas frias de storage. Essa camada é a que resolve a maioria dos incidentes do dia a dia, como erro humano, falha de atualização ou corrupção pontual de dados. Em seguida vem a camada de proteção contra desastres e ransomware, usando storage imutável (WORM), múltiplas contas ou até múltiplas nuvens, com chaveamento de acesso rígido e segregação de funções.
A terceira camada é a de retenção de longo prazo e conformidade, importante para setores regulados que precisam guardar registros por anos, mas sem deixar os dados vulneráveis. Aqui entram criptografia de ponta a ponta, rotação de chaves gerenciadas por HSM, além de políticas detalhadas de ciclo de vida de dados, garantindo que aquilo que não precisa ser mantido seja destruído adequadamente, reduzindo superfície de ataque. Uma das melhores práticas de backup e disaster recovery em nuvem em 2026 é assumir que um dia seu ambiente principal será comprometido e que o atacante tentará apagar ou criptografar os próprios backups; por isso, isolar contas, usar mecanismos de “air gap lógico” e ativar imutabilidade por tempo mínimo são hoje praticamente obrigatórios, e não mais opcionais para organizações sérias.
Passo 3: Definir RTO, RPO e topologia de recuperação na nuvem
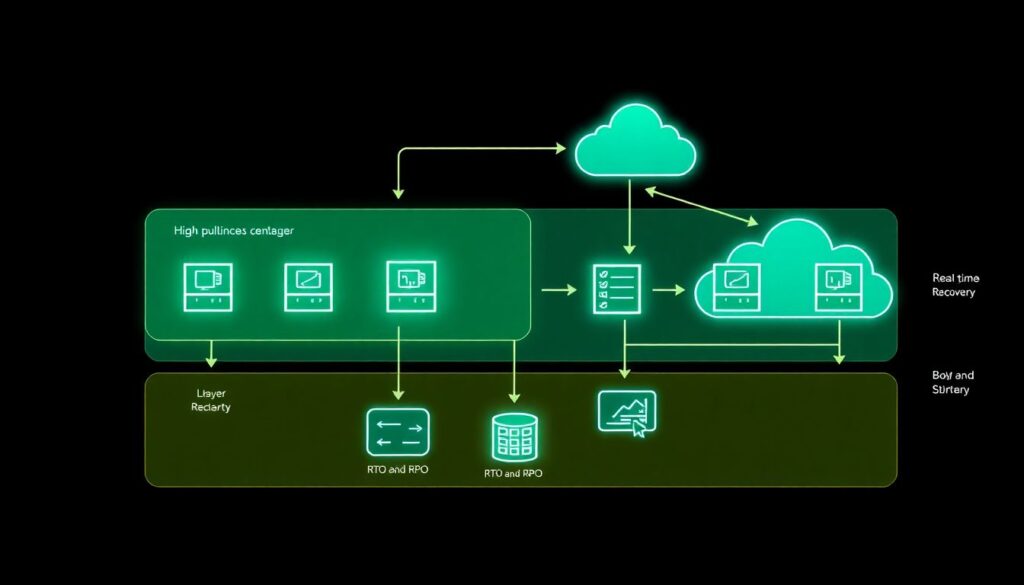
Com as camadas definidas, entra o momento de casar os objetivos de negócio (RTO e RPO) com as opções técnicas. Para workloads muito críticos, muitas empresas em 2026 optam por topologias de alta disponibilidade multi-zona ou até multi-região, combinadas com replicação síncrona ou quase síncrona. Isso encarece a operação, mas reduz drasticamente o tempo de recuperação, porque a aplicação continua rodando em outro ponto geográfico praticamente sem intervenção manual. Já para sistemas de suporte, faz mais sentido aceitar RTO maior, usando backups diários ou horários em storage mais barato, restaurando apenas sob demanda. Aqui, a conversa de custos precisa ser transparente, mostrando para as áreas de negócio quanto custa reduzir de um RTO de quatro horas para quinze minutos, evitando promessas irrealistas.
Em 2026, novos padrões também surgiram para workloads em containers e aplicações nativas de nuvem. Não basta salvar discos de máquinas; é preciso capturar estado de clusters Kubernetes, definições de serviços, secrets, configurações de rede e dependências como filas e tópicos de mensageria. O erro clássico dos iniciantes é achar que um snapshot de VM resolve tudo, esquecendo de componentes gerenciados (bancos PaaS, filas, funções serverless), que precisam de políticas específicas de backup e exportação. Um bom passo é documentar, para cada aplicativo, como reconstruí-lo do zero em uma região vazia: quais backups restaurar, quais scripts rodar, quais parâmetros ajustar. Esse exercício força a equipe a pensar além da tecnologia e enxergar o fluxo real de recuperação.
Passo 4: Escolher serviços e ferramentas modernas de backup e DR
Quando se fala em serviços de backup e recuperação de desastres para empresas hoje, o cardápio é bem mais sofisticado do que há alguns anos. Além das soluções nativas dos grandes provedores de nuvem, existem plataformas independentes especializadas em ambientes híbridos e multi-cloud, capazes de orquestrar backups de VMs on-premises, clusters Kubernetes, bancos as a service e até aplicações SaaS como Microsoft 365 ou Google Workspace. Na escolha, vale olhar para pontos como suporte a imutabilidade, detecção de ransomware baseada em comportamento, automação de testes de restore e integração com sistemas de identidade corporativa. Também é importante garantir que os metadados dos backups — catálogos, índices, logs — estejam protegidos com o mesmo rigor que os dados, já que um ataque bem-sucedido costuma mirar justamente esses pontos.
Outro detalhe relevante em 2026 é a presença massiva de workloads de dados e IA em escala, com data lakes, warehouses e pipelines que rodam 24×7. Nesses cenários, fazer backup tradicional de grandes volumes diariamente muitas vezes é inviável, tanto em custo quanto em janela de tempo. Em vez disso, predominam abordagens de versionamento de dados, snapshots incrementais frequentes, replicação contínua e políticas de conservação por camada (hot, warm, cold). Para iniciantes, a recomendação é não sair comprando a solução mais cara do mercado; começar com recursos nativos do provedor de nuvem, aderindo a boas práticas, e só então evoluir para ferramentas especializadas se houver ganhos claros de gestão, automação ou visibilidade, evitando a armadilha de ter cinco ferramentas diferentes e nenhum processo maduro.
Passo 5: Escrever (de verdade) o plano de recuperação de desastres

Ferramenta sem plano escrito é quase tão inútil quanto não ter backup algum. Um plano de recuperação de desastres em cloud computing precisa ser um documento objetivo, que qualquer pessoa da equipe consiga seguir mesmo sob pressão, às três da manhã, quando tudo está fora do ar. Isso inclui quem aciona o plano, em quais situações, qual é a cadeia de contato, quais passos seguir para declarar desastre, quais sistemas restaurar primeiro, qual a ordem de execução dos playbooks de infraestrutura e de aplicação, e como comunicar clientes, parceiros e órgãos reguladores. Em 2026, muitas organizações adotam playbooks “as code”, versionados em repositórios Git, com scripts de automação integrados, reduzindo dependência de conhecimento tácito.
Um erro muito comum, especialmente em empresas menores ou equipes sobrecarregadas, é escrever o plano uma vez e nunca mais atualizar. Ambientes em nuvem mudam o tempo todo: novas VPCs, novos serviços gerenciados, novas integrações. Se o plano não acompanhar essas mudanças, a chance de falhar justamente quando é mais necessário é altíssima. Para evitar isso, vincule atualizações do plano a eventos de mudança relevantes — novos sistemas críticos em produção, migrações para outra região, adoção de novas tecnologias de dados — e defina um ciclo mínimo de revisão, por exemplo trimestral. E, principalmente, deixe claro o que é decisão técnica automática e o que exige avaliação de negócio, para que ninguém fique travado por insegurança na hora de decidir restaurar para outra região ou acionar um provedor secundário.
Passo 6: Testar, quebrar e ajustar — o ciclo contínuo
Talvez o ponto mais negligenciado, mas também o mais determinante, seja o teste de desastres. Não basta saber que backups são feitos; é preciso provar, periodicamente, que você consegue restaurar dentro dos RTOs e RPOs acordados. Em 2026, ficou mais comum usar técnicas inspiradas em chaos engineering, simulando falhas em regiões, indisponibilidade de serviços gerenciados ou perda de credenciais, para ver se o plano se sustenta. O ideal é ter um calendário com testes parciais (restauração de um banco, recuperação de um microserviço crítico) e exercícios mais amplos, pelo menos uma ou duas vezes por ano, onde se simula de ponta a ponta um cenário de indisponibilidade severa, com participação de equipes técnicas e gestores de negócio, medindo tempos de resposta e qualidade da comunicação.
Para iniciantes, isso pode parecer intimidador, mas começar pequeno ajuda muito. Comece restaurando um banco não crítico em um ambiente de teste e verificando se os dados fazem sentido; depois, simule a perda de uma VM de aplicação e documente quanto tempo leva para que tudo volte a funcionar. Cada teste deve gerar lições aprendidas: gaps de documentação, dependências não mapeadas, permissões insuficientes, scripts que falham em determinadas regiões. Uma das melhores práticas atuais é integrar relatórios de teste de DR a indicadores de risco corporativo, mostrando para a alta gestão a diferença entre “acreditamos que funciona” e “sabemos que funciona porque testamos na semana passada”. Essa visibilidade ajuda a garantir orçamento contínuo e apoio político para evoluir o plano, em vez de tratá-lo como um projeto pontual que envelhece rapidamente.
Erros comuns e armadilhas em 2026 (e como evitá-los)
Alguns erros se repetem ano após ano, mas ganham contornos mais perigosos no contexto atual. O primeiro é confiar demais em redundância e achar que alta disponibilidade substitui backup. Replicar dados de forma síncrona entre zonas ou regiões protege contra falhas de infraestrutura, mas não contra exclusões acidentais, corrupção lógica ou ransomware; nesses casos, você só está copiando o problema para todos os lados. Outro erro clássico é usar a mesma conta, mesmas credenciais e mesmos perfis de acesso para produção e backup, facilitando que um atacante com privilégios amplos apague tudo de uma vez. Em 2026, a adoção de modelos de Zero Trust e segregação forte de identidades para administração de backups é praticamente mandatória para qualquer organização que leve segurança a sério.
Há também a armadilha do “backup invisível”, em que a empresa acredita que o provedor SaaS cuida de tudo e descobre tarde demais que a responsabilidade por retenção e restauração granular de dados é compartilhada. Isso vale para e-mail corporativo, ferramentas de colaboração, CRM e outras aplicações amplamente usadas. A dica para novatos é sempre ler a fundo os SLA e documentos de responsabilidade compartilhada, verificando quais garantias o fornecedor realmente oferece em termos de retenção, histórico, restauração e resposta a incidentes, antes de assumir que “está tudo coberto”. E, claro, documentar estratégias específicas para esses sistemas, que muitas vezes exigem integrações de backup via API com soluções de terceiros, formando um ecossistema mais completo de proteção.
Tendências atuais: IA, multi-cloud e resiliência como código

Em 2026, algumas tendências mudaram bastante a forma de montar soluções de continuidade de negócios na nuvem. A primeira é o uso pesado de IA e machine learning para detecção de anomalias em padrões de acesso e volume de escrita, ajudando a identificar incidentes de ransomware minutos após o início, antes que todo o ambiente seja comprometido. Outra é o avanço do conceito de “resilience as code”: toda a lógica de backup, replicação, failover e testes é descrita em código declarativo, versionada, revisada em pull requests e implantada via pipelines CI/CD, o que diminui erros manuais e aumenta a previsibilidade. Junto com isso, cresce a adoção de arquiteturas multi-cloud, seja por motivos regulatórios, seja por busca de resiliência adicional, tornando ainda mais importante escolher ferramentas que não fiquem trancadas em um único provedor.
Ao mesmo tempo, o custo e a complexidade aumentam quando tudo é distribuído demais, o que exige uma governança mais madura para não transformar a resiliência em um labirinto. Ferramentas de observabilidade que cruzam métricas de backup, logs de segurança e saúde de aplicações ajudam a dar visibilidade, mas só funcionam se a empresa tiver processos claros para reagir a alertas. Para quem está começando agora, a recomendação é não pular diretamente para o cenário mais complexo de multi-cloud ativa em tudo; comece garantindo um bom nível de proteção em um único provedor, aplicando as melhores práticas de backup e disaster recovery em nuvem, e vá introduzindo redundâncias adicionais de forma incremental, sempre com testes e métricas, em vez de se apoiar em promessas genéricas de “100% de disponibilidade” que não se sustentam na prática.
Fechando o ciclo: backup, desastre e negócio no mesmo painel
No fim das contas, montar uma estratégia sólida em nuvem não é só questão de tecnologia, mas de cultura e alinhamento. Backup, recuperação de desastres e continuidade não podem ficar isolados em um canto de TI, desconectados do planejamento estratégico. Em 2026, as empresas mais bem preparadas são aquelas que tratam resiliência como atributo de produto: cada novo sistema já nasce com objetivos de RTO e RPO definidos, scripts de restauração automatizados, monitoramento integrado e métricas de risco acompanhadas pelos times de produto e pela gestão executiva. Ao seguir uma abordagem passo a passo — entender o que é crítico, desenhar camadas de proteção, definir objetivos claros, escolher serviços adequados, escrever e testar o plano — você sai da lógica reativa e passa a operar com previsibilidade, preparado tanto para falhas cotidianas quanto para cenários extremos que, cedo ou tarde, acabam acontecendo.