
Serverless security depends on hard isolation of functions, least‑privilege IAM, robust secrets handling, and continuous visibility. Start by defining a clear modelo de ameaças e compliance para aplicações serverless, then apply configuração baselines, runtime monitoring, and incident playbooks. Treat dependencies and CI/CD as first‑class attack surfaces and automate every control you can.
Essential security checklist for serverless deployments
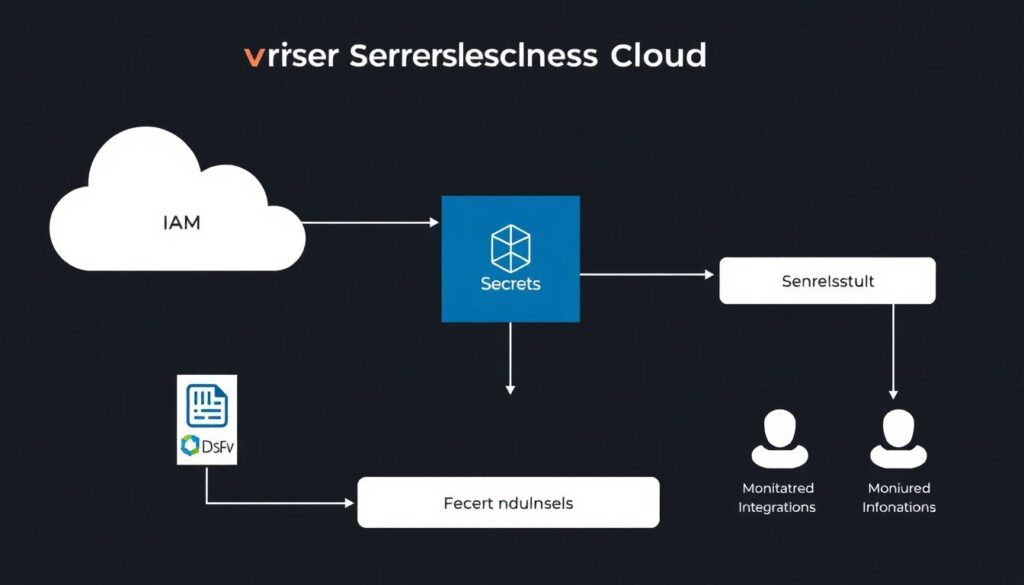
- Map your serverless threat model, including tenants, data sensitivity, and external integrations.
- Harden IAM with least privilege, short‑lived credentials, and strong identity boundaries per function.
- Adopt centralized secrets management; remove all secrets from code and environment files.
- Control third‑party dependencies with SBOMs, automated SCA, and pinned versions.
- Enable end‑to‑end logging and metrics to support proteção de funções serverless na nuvem in real time.
- Define incident playbooks tailored to serverless workflows and compliance requirements.
- Periodically reassess segurança em serverless melhores práticas against your cloud provider’s updates.
Threat landscape specific to serverless platforms
Serverless reduces some risks (server patching, OS hardening) but exposes new ones at the function, event, and identity layers. This section focuses on when serverless is a good fit, and when security or compliance concerns suggest caution.
- When serverless is well suited from a security perspective
- Workloads with bursty or unpredictable traffic, benefiting from provider‑managed scaling and isolation.
- Event‑driven integrations (webhooks, queue processing, scheduled tasks) with short‑lived execution.
- APIs that can use fine‑grained function‑level permissions and zero‑trust networking controls.
- Greenfield projects where you can adopt segurança em serverless melhores práticas from day one.
- When to be cautious or avoid serverless
- Workloads requiring dedicated hardware or strict residency controls not available in your region (pt_BR or otherwise).
- Legacy apps needing long‑running processes, custom kernels, or low‑level networking.
- Highly regulated data flows where you cannot map the full modelo de ameaças e compliance para aplicações serverless to existing controls.
- Scenarios demanding deep host‑level forensics that your provider cannot support on serverless runtimes.
- High‑level threat categories for serverless
- Event injection and data validation failures across triggers (HTTP, queues, storage, streams).
- Over‑privileged roles and misconfigured identities across functions and microservices.
- Insecure secrets handling (hard‑coded API keys, environment leaks, misused KMS).
- Supply‑chain attacks via dependencies, CI/CD, or configuração as code templates.
- Abuse of concurrency and cost‑amplification attacks targeting autoscaling behavior.
Common attack vectors in Functions-as-a-Service environments
Focus on what you need in place to detect, test, and block attacks against Functions‑as‑a‑Service (FaaS). This includes tooling, minimum permissions, and recommended observability baselines.
- Typical attack vectors to cover
- Deserialization and injection flaws in function handlers exposed via HTTP APIs.
- Abuse of event payloads from queues, storage events, or pub/sub messages.
- Token theft via insecure logs, debug endpoints, or temporary storage buckets.
- Privilege escalation through shared IAM roles across multiple functions.
- Supply‑chain attacks on open‑source libraries and build tools.
- Baseline tools and access you will need
- Access to cloud IAM console and CLI to inspect and edit roles/policies.
- Logging and monitoring services enabled for all functions, including metrics and traces.
- At least one vulnerability scanner and SCA solution as ferramentas de segurança para arquitetura serverless.
- Source control access to review build pipelines, IaC templates, and deployment scripts.
- Read‑only access to configuration of API gateways, queues, topics, and storage buckets.
- Risk to control mapping for serverless workloads
| Major serverless risk | Example scenario | Primary mitigations and controls |
|---|---|---|
| Over‑privileged function identities | All functions share a single admin‑like role | Per‑function roles, least‑privilege policies, periodic IAM review, and access analyzer tools |
| Event injection and unvalidated inputs | Malicious JSON in queue message triggers unsafe behavior | Centralized validation libraries, schema enforcement, WAF on HTTP triggers, and strict parsing |
| Secrets exposure | API keys in environment variables or code repo | Managed secrets service, envelope encryption, no secrets in code, and rotation automation |
| Insecure dependencies | Vulnerable library used by many functions | Automated SCA, SBOM, pinned versions, and dependency update workflows |
| Insufficient monitoring | No logs for failed invocations or timeouts | Mandatory logging for all functions, structured logs, metrics, alerts, and trace sampling |
| Abuse of concurrency and cost | Attacker triggers massive parallel invocations | Concurrency limits, rate limiting, quotas, and cost‑anomaly detection |
Identity, access control and secrets management best practices
Preparation checklist before changing IAM or secrets in production:
- List all functions, their triggers, and which resources they access (DBs, queues, storage, APIs).
- Export current IAM roles and policies for backup and later comparison.
- Confirm that you have test and staging environments mirroring production permissions.
- Identify every place secrets are currently stored: code, CI/CD variables, config files, and vaults.
- Ensure audit logging is enabled for IAM changes and secrets access events.
- Isolate identities per function or microservice
Create a dedicated execution role or principal for each function or tightly related group of functions. Avoid shared admin‑type roles. This enables clear blast‑radius boundaries and supports proteção de funções serverless na nuvem based on minimal privileges.- Map one role to one function where possible, especially for internet‑facing APIs.
- Block use of long‑lived access keys; prefer role assumption and short‑lived tokens.
- Apply least‑privilege IAM policies
Replace broad permissions (such as full access to storage or databases) with resource‑level and action‑level permissions. Only allow operations that the function actually needs.- Use policy conditions (IP ranges, VPC IDs, tags) to further narrow access.
- Review permissions at least quarterly and after each major feature release.
- Separate control‑plane and data‑plane access
Functions should rarely need permissions to manage infrastructure (create roles, queues, or buckets). Restrict them to data‑plane APIs and keep control‑plane access for CI/CD or operators.- Audit existing roles for any infrastructure‑management actions and remove them.
- Ensure CI/CD roles are different from runtime roles used by functions.
- Centralize secrets in a managed secrets service
Move all credentials, API keys, and encryption keys into a dedicated secrets manager or key management service. No secrets should live in source code, images, or plain environment variables.- Refactor functions to resolve secrets at runtime using SDK calls to the secrets service.
- Enable automatic rotation for database passwords and external API keys wherever supported.
- Encrypt sensitive configuration and outputs
For configuration values that cannot be in a vault, use envelope encryption with managed keys. Ensure logs and object storage used by functions are encrypted at rest and in transit.- Configure HTTPS/TLS enforcement for all public and internal endpoints.
- Use customer‑managed keys for highly sensitive workloads subject to strict compliance.
- Implement just‑in‑time access for operators
Administrative actions (manual replays, direct DB access) should use ephemeral privileges, not permanent admin roles.- Adopt approval workflows for granting temporary elevated roles.
- Log all privileged operations and review them regularly.
- Monitor and alert on anomalous identity and secrets usage
Feed access logs to detection tools that recognize unusual patterns: new regions, sudden spikes in secrets requests, or roles used from unexpected services.- Create baseline metrics for normal invocation and secrets access rates.
- Set alerts for deviations and integrate them into your on‑call workflow.
- Document and test your IAM and secrets model
Keep living documentation of which function can access which resource and why. Regularly test that least‑privilege holds using automated checks and manual attempts.- Use policy simulation tools to validate changes before deployment.
- Include IAM and secrets checks in code review templates and security sign‑offs.
Securing the build pipeline and third‑party dependencies
Use this checklist to validate that your CI/CD and supply chain are not the weakest link when you try to como mitigar riscos de segurança em serverless.
- All function repositories use branch protection, mandatory reviews, and signed commits for critical services.
- CI/CD runners and agents run with minimal permissions and do not reuse production runtime roles.
- Dependency manifests specify explicit versions (no unbounded ranges) and are locked via a lockfile mechanism.
- Software Composition Analysis (SCA) runs on every merge and deployment, blocking known critical vulnerabilities.
- Static Application Security Testing (SAST) is integrated into the pipeline for all languages used in functions.
- Build artifacts are stored in a trusted registry, with integrity checks (hashes, signatures) verified at deploy time.
- Infrastructure as Code templates for serverless (SAM, Serverless Framework, Terraform, etc.) are scanned for misconfigurations.
- Secrets and tokens used in CI/CD are stored in a secure vault, never hardcoded in pipeline definitions.
- Separate pipelines exist for dev, staging, and production, with promotion gates and manual approvals for production.
- Regular reviews of third‑party plugins, actions, or build steps are performed to reduce hidden supply‑chain risks.
Runtime protection, logging and anomaly detection
Typical mistakes in production monitoring and protection can nullify many design‑time controls. Avoid the following issues when hardening segurança em serverless melhores práticas at runtime.
- Deploying functions without enabling centralized, structured logging for each invocation and error.
- Failing to capture and store correlation IDs across API gateway, functions, queues, and downstream services.
- Relying only on averaged metrics instead of setting thresholds for errors, timeouts, and cold‑start anomalies.
- Not configuring per‑function concurrency limits, allowing unbounded parallel execution and potential cost attacks.
- Ignoring security signals from WAFs or API gateways fronting your serverless endpoints.
- Omitting traces, which makes it hard to distinguish between application bugs and active attacks.
- Keeping debug logging permanently on, which can leak secrets, tokens, and user data into log streams.
- Lack of real‑time alert routing to on‑call engineers, leading to long dwell times for serverless incidents.
- No periodic tests of log retention and access controls, risking loss of evidence for investigations.
- Not integrating runtime signals with ferramentas de segurança для arquitetura serverless such as SIEM and IDS, limiting correlation.
Response playbooks and compliance for serverless incidents
Different operational and governance models can be used to respond to serverless incidents and enforce a consistent modelo de ameaças e compliance para aplicações serverless. Choose based on team maturity and regulatory context.
- Centralized cloud security team with shared playbooks
A single security team owns incident runbooks, detection logic, and compliance mapping for all serverless workloads.- Best for organizations with many small product teams and strong platform capabilities.
- Simplifies audits and reporting across multiple business units in regions like pt_BR.
- Product‑aligned incident ownership with security as advisors
Each product team owns playbooks for its functions, with security providing standards and tooling.- Works well when teams have solid operational skills and need autonomy.
- Requires clear minimum baselines and periodic reviews for alignment with regulations.
- Hybrid model with platform‑level guardrails
A platform team enforces guardrails (logging, WAF, IAM baselines), while individual teams tailor playbooks.- Balances flexibility and consistency, often ideal when scaling serverless to many domains.
- Supports unified reporting on como mitigar riscos de segurança em serverless across the portfolio.
- Managed security services for small teams
Outsource some detection and response functions to a trusted provider with serverless experience.- Useful for small organizations that lack a 24/7 SOC capability.
- Ensure contracts explicitly cover serverless signals and compliance reporting needs.
Practical clarifications for recurring operational scenarios
How do I start a basic threat model for a new serverless API?

List all entry points (HTTP routes, events), data types processed, and external services called. For each, ask what can go wrong, who might attack, and which controls already exist. Use this to prioritize least‑privilege IAM, input validation, and logging coverage.
Which secrets should be moved first into a managed secrets service?
Start with the most sensitive and widely used secrets: database credentials, signing keys, and third‑party API tokens. These typically have broad impact if leaked. Migrate them into a vault, update functions to fetch them at runtime, and enable rotation.
How often should I review IAM roles for serverless functions?
Review IAM at least every few months and after any major feature or integration change. Use automated analysis tools to flag unused permissions, then tighten policies accordingly. Treat IAM reviews as part of your regular serverless release cycle.
What is the minimum logging I should enable for production serverless?
Log every invocation, including start, end, and errors, with correlation IDs and caller identity where possible. Ensure logs are centralized, retained per your compliance requirements, and searchable. Add alerts for spikes in errors, throttling, or latency.
How can I limit the blast radius if one function is compromised?
Give each function its own role and minimal permissions, and avoid shared databases or buckets unless necessary. Set strict network and data‑access boundaries. This way, a compromised function cannot pivot easily to other services or exfiltrate large amounts of data.
Do I need separate incident playbooks for serverless and non‑serverless workloads?
Yes, you should adapt playbooks to cover serverless‑specific aspects such as event replay, concurrency control, and per‑function rollbacks. However, keep them aligned with your broader incident management framework to reuse communication channels and escalation paths.
When should I bring in specialized tools for serverless security?
Introduce specialized ferramentas de segurança para arquitetura serverless once you have basic IAM, logging, and CI/CD controls in place. These tools are most effective when they can consume your existing telemetry and policies to surface deeper, context‑aware findings.