Por que proteger workloads serverless virou assunto sério
Quando serverless apareceu de vez, muita gente enxergou quase uma “mágica”: você escreve código, faz deploy e deixa que AWS, Azure ou GCP cuidem do resto. Sem servidor para configurar, sem patch do sistema operacional, sem depender de um time de infraestrutura enorme. Só que esse conforto trouxe um efeito colateral perigoso: a sensação de que segurança “vem por padrão”. Na prática, segurança serverless na nuvem não é automática; ela só muda de forma. Em vez de pensar em portas abertas em máquinas virtuais, o foco migra para permissões granulares, dependências de terceiros, eventos maliciosos e erros de configuração em escala. Ou seja, o risco não desaparece, ele se desloca para novas camadas – e quem não acompanha essa mudança acaba se expondo sem perceber.
Um pouco de história: do servidor debaixo da mesa ao serverless
Se voltarmos algumas décadas, o mundo rodava em servidores físicos, muitas vezes dentro do próprio escritório. Segurança era firewall, antivírus, controle de acesso físico ao datacenter e, com sorte, algum monitoramento de rede. Depois veio a virtualização, os data centers gerenciados e, finalmente, a nuvem pública. A cada etapa, parte da responsabilidade passava para o provedor, mas o modelo mental continuava parecido: “tenho uma máquina, preciso protegê-la”. O surgimento das funções como serviço, como AWS Lambda, Azure Functions e Google Cloud Functions, que são a espinha dorsal dos workloads serverless, quebrou esse paradigma. Agora você não enxerga sistema operacional, não gerencia patch, quase não toca na rede. A sensação é libertadora; ao mesmo tempo, cria uma zona cinzenta sobre onde exatamente termina a segurança do provedor e começa a sua, o que torna ainda mais importante compreender o novo modelo de ameaça.
Princípios básicos de segurança em workloads serverless
A base de qualquer estratégia de proteção de workloads serverless aws azure gcp é entender o modelo de responsabilidade compartilhada. O provedor garante a segurança da infraestrutura subjacente, mas tudo o que acontece dentro da sua conta, da sua aplicação e das suas configurações é problema seu. Em serverless, isso significa cuidar de identidade e acesso com obsessão, limitando o que cada função pode fazer ao mínimo estritamente necessário, aplicar validação rigorosa de entrada em cada evento que dispara o código e tratar dependências externas como potenciais vetores de ataque. Além disso, observabilidade deixa de ser luxo e vira pré-requisito: sem logs ricos, correlação de eventos e métricas de comportamento, você não consegue perceber quando uma função começa a agir de forma estranha, seja por bug, abuso ou invasão.
Modelos de ameaça específicos para ambientes serverless
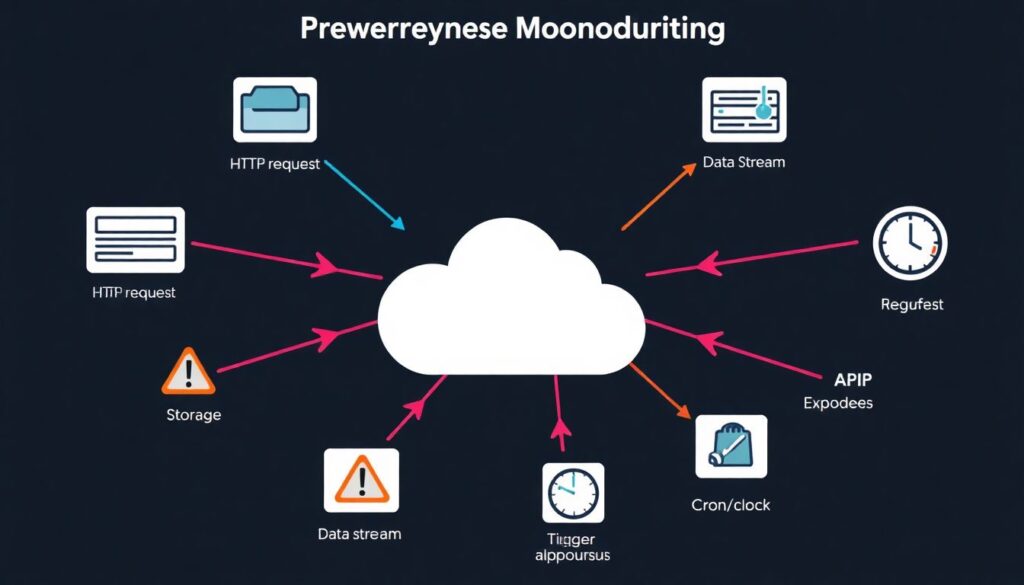
Ao falar de modelos de ameaça para serverless, o ponto de partida é entender como o código é acionado. Funções podem ser disparadas por HTTP, mensagens em filas, eventos de storage, streams, cron e por aí vai. Cada tipo de gatilho abre uma frente: exposição indevida de APIs, mensagens maliciosas enfileiradas em massa, uploads contendo payloads perigosos ou fluxos de dados manipulados por atacantes internos. Outro elemento importante é a curta duração das execuções: análises tradicionais que buscam persistência de malware podem falhar em detectar ataques relâmpago, em que o invasor entra, faz o que precisa e sai em segundos. Por fim, a complexidade da orquestração em arquiteturas orientadas a eventos cria riscos de escalada lateral: uma função comprometida pode publicar mensagens que disparam outras funções com privilégios maiores, se o desenho de permissões não for pensado com cuidado desde o início.
Riscos mais comuns em workloads serverless
Alguns riscos aparecem de forma tão recorrente que já formam um “top 5” informal. Primeiro, permissões excessivas em funções, que muitas vezes recebem papéis padrão com acesso amplo a serviços e dados sensíveis, abrindo espaço para abuso se a função for explorada. Segundo, validação fraca de entrada, especialmente em funções usadas como backend de APIs públicas, o que reabre velhas conhecidas como injeção, XSS e manipulação de parâmetros. Terceiro, dependências desatualizadas, já que muitos times confiam cegamente em bibliotecas de terceiros sem política clara de atualização. Quarto, segredos expostos em variáveis de ambiente ou código-fonte, algo mais grave ainda em ambientes que escalam rapidamente para centenas de instâncias. Por último, falta de visibilidade: sem métricas e logs consolidados, incidentes passam despercebidos até que se tornem vazamentos ou contas de nuvem surpreendentemente altas.
Controles recomendados: o básico bem feito

Antes de pensar em soluções sofisticadas, vale garantir que os controles fundamentais estão de pé. Isso começa com uma política rígida de IAM: separar funções por domínio de responsabilidade, limitar cada uma ao conjunto mínimo de ações e recursos, e revisar essas permissões periodicamente. Outro pilar é proteger os pontos de entrada: usar gateways de API com autenticação forte, limitação de taxa e inspeção básica ajuda a filtrar muito ruído. No nível de código, padrões de desenvolvimento seguro precisam ser internalizados pelo time, com foco em sanitização de entrada e saída. Gestão de segredos deve ser feita via serviços dedicados, não por variáveis de ambiente em texto puro. E, complementando tudo, um pipeline de CI/CD que inclua testes de segurança automatizados transforma esses controles em rotina, em vez de depender da memória ou boa vontade de alguém na hora do deploy.
Ferramentas e automação para proteger aplicações serverless
Na prática, quase ninguém consegue manter um ambiente serverless seguro apenas “na mão”. É aqui que entram as ferramentas de segurança para aplicações serverless, que vão desde scanners de configuração de nuvem e análise de infraestrutura como código até soluções específicas para monitorar funções em tempo de execução. Muitas dessas ferramentas se integram diretamente com o pipeline de CI/CD, avisando sobre dependências vulneráveis, políticas IAM perigosas ou endpoints expostos assim que o desenvolvedor abre um pull request. Em produção, plataformas mais avançadas aplicam detecção de comportamento anômalo em logs de execução, identificando padrões suspeitos, como picos de chamadas incomuns ou tentativas de acessar serviços não permitidos. Automatizar pelo menos parte dessa vigilância reduz o atrito com o time de desenvolvimento e torna mais viável manter um padrão consistente, mesmo quando a quantidade de funções começa a crescer rapidamente.
Plataformas cloud native e abordagem unificada
À medida que arquiteturas ficam mais distribuídas, fica claro que proteger apenas a função isolada já não basta. Uma plataforma de segurança cloud native para serverless tenta enxergar o conjunto: funções, filas, tópicos, bancos de dados gerenciados, storage e serviços auxiliares. Em vez de olhar só para uma Lambda ou Function específica, ela correlaciona eventos entre múltiplos componentes da aplicação. Esse tipo de abordagem unificada ajuda a detectar movimentos laterais em fluxo de eventos, abuso de credenciais e erros de configuração que só fazem sentido quando vistos em contexto. Além disso, usar uma solução que também cubra contêineres, Kubernetes e workloads tradicionais simplifica o dia a dia de times que vivem em ambientes híbridos, onde serverless é apenas uma parte do quebra-cabeça. O trade-off costuma ser a necessidade de ajustes finos para evitar excesso de alertas, mas o ganho de visibilidade compensa o esforço inicial.
Boas práticas específicas para funções Lambda e similares
Embora os princípios sejam parecidos entre provedores, vale destacar que melhores práticas de segurança lambda functions viraram quase um manual extra-oficial para quem trabalha com serverless. Isso inclui empacotar apenas o necessário no código, evitando bibliotecas gigantescas e superfícies de ataque desnecessárias, usar layers com critério e revisar sua origem, e cuidar do tempo de execução para não abrir brechas de negação de serviço. Outro ponto importante é definir limites de memória e tempo de execução coerentes, tanto para controlar custos quanto para reduzir o impacto de execuções maliciosas que tentem explorar a escalabilidade automática. Além disso, monitorar erros e exceções de forma centralizada evita que informações sensíveis escapem em mensagens de log, o que é fácil de acontecer quando o time ainda está ajustando a observabilidade. Em resumo, tratar cada função como um microserviço com responsabilidades claras ajuda muito a reduzir riscos.
Comparando abordagens de segurança: manual, integrada e especializada
Na prática, vemos três grandes jeitos de encarar a segurança em serverless. O primeiro é o caminho “manual”, em que o time confia principalmente em boas práticas documentadas e revisões de código. É simples e barato, mas depende fortemente de disciplina e tende a não escalar bem. O segundo é a abordagem integrada, em que a segurança é costurada no pipeline de CI/CD com scanners de IaC, análise de dependências e testes automatizados. Essa linha equilibra esforço humano e automação e costuma ser um bom meio-termo. Por fim, há a opção de adotar soluções especializadas em serverless, muitas vezes parte de uma suíte maior de segurança de nuvem, capazes de inspecionar execuções e correlacionar eventos em tempo real. Aqui o investimento é maior, mas faz sentido em ambientes críticos ou muito dinâmicos. Em geral, a combinação mais saudável junta práticas manuais bem definidas, automação no pipeline e, quando o contexto pede, ferramentas especializadas para fechar lacunas.
Equívocos frequentes sobre segurança serverless
Alguns mitos insistem em sobreviver quando falamos de serverless. Um dos mais perigosos é a ideia de que “se está na nuvem, está seguro”, como se o provedor cuidasse de tudo, inclusive dos bugs no seu código e das permissões que você mesmo configurou de forma ampla demais. Outro engano é achar que, por não haver servidor visível, não existem vulnerabilidades de infraestrutura; na prática, configurações erradas em gateways de API, storage ou filas continuam sendo portas de entrada comuns. Também é comum subestimar o impacto de pequenas funções auxiliares, vistas como inofensivas; se elas tiverem credenciais fortes ou acesso a dados sensíveis, podem virar o elo fraco da cadeia. Por fim, há quem veja a automação como solução mágica, esquecendo que ferramentas só funcionam bem quando alguém configura, revisa e interpreta seus alertas. Sem essa camada humana, até o melhor produto do mercado vira só mais uma fonte de ruído.
Conclusão: segurança como parte natural do design
No fim das contas, proteger workloads serverless não exige poderes especiais, mas sim um ajuste de mentalidade. Em vez de pensar em firewall e patch de sistema operacional, você passa a projetar fluxos de eventos, permissões mínimas e validação rigorosa em cada entrada possível. A combinação de princípios sólidos, automação sensata e uma visão integrada da aplicação cria uma base robusta, na qual segurança deixa de ser um “add-on” e passa a fazer parte do próprio desenho da solução. Cada função, fila ou tópico é tratado como peça crítica de um sistema maior, e não como detalhe irrelevante. Essa mudança reduz surpresas desagradáveis, melhora a resiliência e, de quebra, aumenta a confiança do time em inovar usando serverless, sabendo que a velocidade de entrega não precisa ser inimiga da proteção dos dados e da continuidade do negócio.