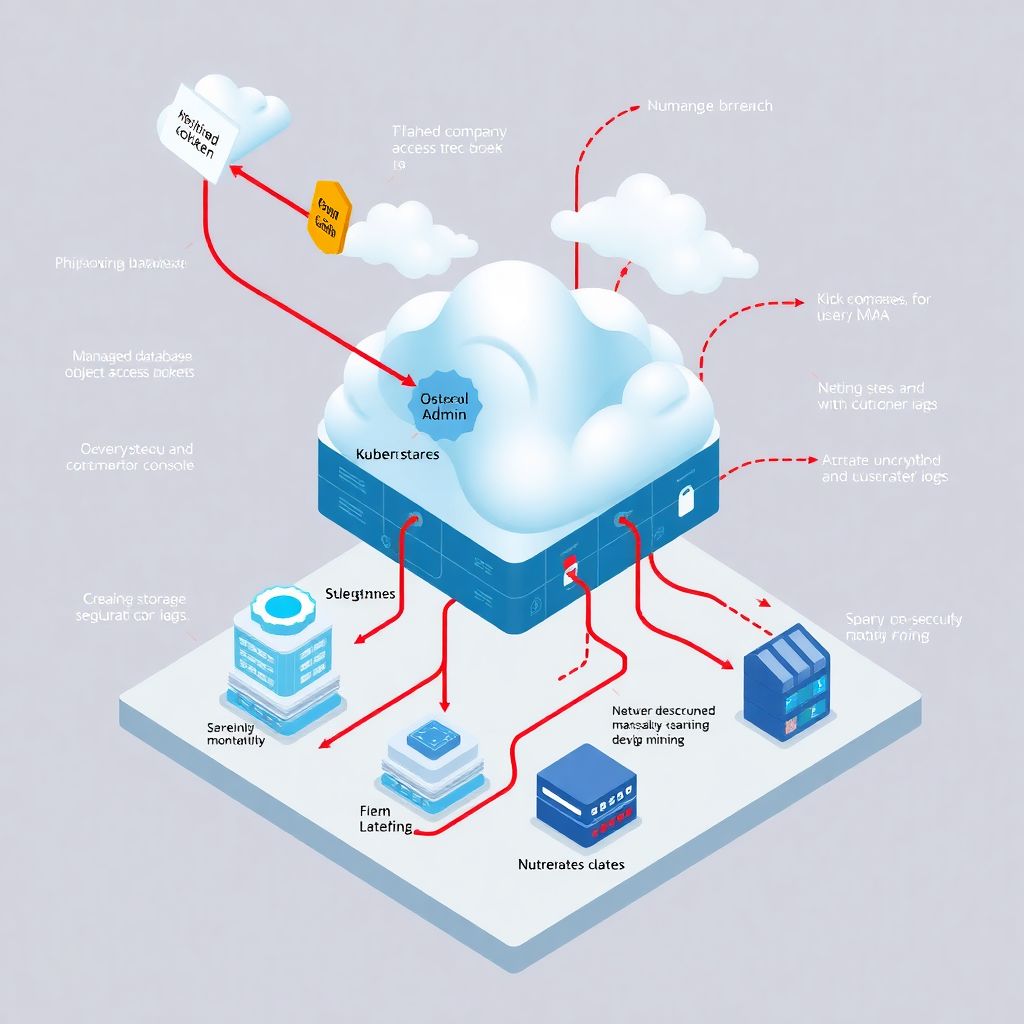
Contexto rápido da violação em ambiente cloud
Imagine uma empresa média usando vários serviços de segurança cloud para empresas: banco de dados gerenciado, storage de objetos e um cluster Kubernetes. Tudo rodando em um único provedor, com integrações via API e VPN site‑to‑site. A violação começou de forma bem comum: credenciais de um desenvolvedor vazaram após phishing e foram usadas para acessar o painel de gestão. A partir daí, o invasor explorou permissões excessivas, falta de segmentação de rede e logs pouco monitorados, movimentando‑se lateralmente por workloads críticos na nuvem.
Como o atacante entrou e o que realmente deu errado
O ponto de entrada foi um token de acesso com privilégios amplos em um repositório privado. Sem MFA forte e sem política de expiração curta, o invasor teve tempo de testar combinações até encontrar uma conta com papel de “DevOps Admin”. A ausência de melhores práticas e políticas de segurança em ambiente cloud ficou clara: roles muito genéricos, grupos sem revisão periódica e nenhuma validação de contexto de acesso, como geolocalização ou device posture. O provedor até oferecia controles nativos, mas quase nada estava ligado ou bem configurado.
Impacto prático na infraestrutura e nos dados
Depois de ganhar acesso amplo, o atacante listou buckets de armazenamento e clusters, identificando onde estavam logs, backups e dados de clientes. Usando scripts simples, criou snapshots não criptografados e moveu cópias para regiões menos monitoradas. Além disso, implantou um container malicioso para mineração de criptomoedas, mascarado como job de manutenção. Ferramentas de monitoramento e detecção de violações em cloud existiam, mas só geravam alertas de capacidade, sem correlação de eventos de identidade, rede e workload, o que atrasou bastante a identificação do incidente.
Abordagem 1: Segurança centrada apenas no provedor cloud
O primeiro modelo muito comum é confiar quase tudo ao próprio provedor: usar IAM nativo, firewall gerenciado, logs padrão e alguns templates prontos. Vantagens: baixa complexidade operacional, custos previsíveis e integração imediata com outras ofertas de segurança em nuvem soluções corporativas. Porém, ficamos presos ao ecossistema de um único vendor, com visibilidade limitada em ambientes multi‑cloud ou híbridos. Outro risco é a falsa sensação de proteção: o provedor garante a segurança “da” nuvem, mas o cliente continua responsável pela segurança “dentro” da nuvem, incluindo configuração, chaves e identidades.
Abordagem 2: Stack própria com múltiplas ferramentas
O segundo caminho é montar um stack customizado: SIEM dedicado, agente em cada VM ou container, scanner de configuração, solução de EDR e plataforma de CSPM. Isso amplia o controle e facilita correlação entre on‑prem e cloud, o que é atrativo para equipes maduras de consultoria em segurança de dados na nuvem. O lado ruim: maior curva de aprendizagem, necessidade de engenheiros especializados e risco de sobreposição de funções entre ferramentas. Sem uma arquitetura bem pensada, o time se afoga em alertas duplicados e dashboards que ninguém consulta no dia a dia.
Abordagem 3: Segurança como código e automação pesada
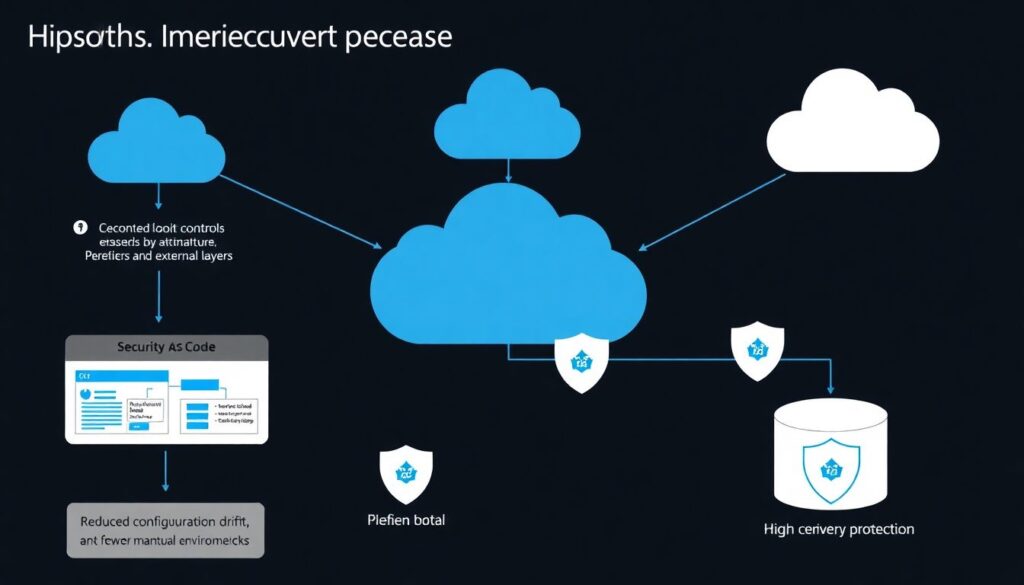
Um terceiro modelo combina controles nativos com camadas externas, mas tudo orquestrado via segurança como código. Policies, roles, regras de firewall e configurações de criptografia são versionadas em repositórios Git e aplicadas via pipelines CI/CD. Isso reduz drift e erros manuais; qualquer desvio é detectado por testes automatizados. O desafio é cultural: times de desenvolvimento precisam tratar controles de segurança como parte do ciclo de release, e não como etapa extra. Quando bem adotado, esse modelo acelerou a resposta ao incidente, permitindo revogar permissões e rolar chaves em minutos, não horas.
Prós e contras das principais tecnologias usadas
Serviços gerenciados de identidade são excelentes para centralizar autenticação e aplicar MFA, mas podem se tornar ponto único de falha se não houver segmentação adequada. Plataformas CSPM ajudam a encontrar configurações abertas, porém não entendem sempre o contexto de negócio, gerando falsos positivos. Já soluções de CNAPP e EDR em containers dão visibilidade profunda, com inspeção de comportamento em runtime, mas exigem recursos de CPU e memória, o que pode aumentar custos de workloads mais sensíveis. A escolha certa depende da maturidade do time e da criticidade dos ativos expostos.
O que funcionou bem durante o incidente
Apesar de todos os problemas, algumas escolhas tecnológicas realmente ajudaram. A segmentação mínima que existia impediu que o atacante alcançasse sistemas de folha de pagamento. Chaves de criptografia gerenciadas pelo cliente limitaram o valor de alguns dados exfiltrados, porque snapshots brutos não eram legíveis fora do ambiente. Além disso, um playbook básico de resposta a incidentes já estava documentado, facilitando a coordenação entre SecOps, SRE e jurídico. Isso mostrou, na prática, que até mesmo controles parciais, quando combinados, conseguem degradar bastante o impacto real de uma violação.
- Aplicar MFA forte e autenticação baseada em contexto para todas as contas privilegiadas;
- Rever periodicamente roles IAM, removendo permissões amplas e não utilizadas;
- Ativar logging detalhado e envio de eventos críticos para um SIEM centralizado;
- Automatizar rotação de chaves, tokens e segredos após qualquer suspeita de comprometimento.
Lições aprendidas: o que deveria ter sido diferente
A análise pós‑incidente mostrou que o maior problema não foi a tecnologia, mas a ausência de um modelo consistente de governança. Se políticas de least privilege tivessem sido aplicadas desde o início, o token vazado teria impacto bem menor. Revisões trimestrais de acessos, combinadas com simulações de ataque, teriam revelado brechas óbvias. Outro ponto foi a falta de processos claros entre TI, desenvolvimento e segurança, o que atrasou decisões de desligar serviços. Em resumo, controles existiam, mas sem dono definido, métricas ou critérios de priorização compatíveis com o risco real.
Recomendações práticas para empresas em situação parecida
Para organizações que se reconhecem neste cenário, faz sentido começar pelo inventário: saber exatamente quais contas, regiões e serviços estão em uso. Em seguida, priorizar dados sensíveis, aplicando criptografia end‑to‑end e segmentação em VPCs distintas. Vale investir em serviços gerenciados que simplifiquem a aplicação de baseline de segurança, antes de adotar ferramentas mais avançadas. Por fim, treinar times de produto e DevOps sobre ameaças comuns e boas práticas de codificação segura evita que decisões de conveniência de curto prazo abram portas permanentes para atacantes oportunistas.
- Definir uma estratégia de identidade única para todos os ambientes (cloud e on‑prem);
- Integrar alertas críticos com canais de resposta rápida, como chat corporativo;
- Testar regularmente os playbooks por meio de exercícios de purple team ou tabletop;
- Medir tempo médio de detecção e resposta para orientar investimentos futuros.
Como escolher entre abordagens e tecnologias concorrentes
Na comparação entre depender só do provedor, montar um stack próprio ou adotar segurança como código, o ponto central é a capacidade interna. Empresas menores tendem a se beneficiar mais de bundles de serviços de segurança cloud para empresas, desde que configurem bem o básico. Organizações com ambientes multi‑cloud ou requisitos regulatórios pesados justificam um stack independente, com foco em correlação entre plataformas. Já quem possui cultura DevOps madura costuma extrair mais valor da automação e de pipelines de compliance, reduzindo o esforço manual e a probabilidade de erro humano.
Sinais de que sua estratégia está madurecendo
Alguns indicadores mostram que a nuvem está mais controlada: número de permissões com privilégios administrativos caindo, ao mesmo tempo em que incidentes reais também diminuem; time reagindo a alertas em minutos, não em horas; e mudanças de infraestrutura passando por revisão automatizada de segurança. Outro sinal positivo é a integração da área de risco e conformidade ao ciclo de desenvolvimento, evitando retrabalho. Quando o discurso deixa de ser “quem quebrou a produção?” e vira “como adaptamos o controle sem travar o release?”, é um bom indício de evolução concreta.
Tendências em segurança cloud até 2026
Olhando para o horizonte de 2026, algumas tendências se destacam: aumento do uso de IA para priorizar alertas e reduzir ruído em incidentes, expansão de plataformas unificadas que juntam CSPM, CWPP e CIEM, e crescimento de modelos de zero trust aplicados a microserviços. A pressão regulatória em setores críticos deve exigir auditoria contínua e verificável de configuração em tempo quase real. Nesse cenário, provedores e parceiros precisarão oferecer segurança em nuvem soluções corporativas mais integradas, com menos fricção na adoção, para que as equipes consigam focar em detecção e resposta.
O papel da consultoria e dos parceiros especializados

Para muitas empresas, não faz sentido construir toda essa capacidade sozinhas. É aí que entram parceiros de consultoria em segurança de dados na nuvem, ajudando a desenhar arquiteturas resilientes, alinhar controles a normas setoriais e implementar pipelines de segurança como código. O diferencial, nos próximos anos, será combinar conhecimento técnico profundo do provedor cloud com entendimento real do negócio. Em vez de entregar relatórios genéricos, bons consultores irão priorizar riscos que impactam diretamente receita, reputação e operações críticas, ajudando a transformar incidentes como essa violação em gatilhos de melhoria contínua.