Historical context: how we got to serverless and why security feels “different”
When people talk about segurança serverless na nuvem, they usually jump straight to IAM policies and function timeouts. But to understand why security in this space feels unusual, it helps to look back a bit. Traditional apps ran on long‑lived servers you could log into, harden, patch, and monitor with familiar tools. With virtual machines and then containers, we kept roughly the same mental model: there is a host, it lives for days or months, and it has a relatively stable surface. Serverless computing flipped that logic — now your code runs in short‑lived functions, often for milliseconds, on infrastructure you never see. Many classic host-based controls vanished overnight: no agents, no SSH, no manual patches. At the same time, business pressure for rapid delivery pushed teams to deploy dozens or hundreds of functions without clear ownership or baselines. The result is a security domain with a lot of power but also plenty of blind spots if you simply transplant old practices without adaptation.
Core principles of serverless security: what actually matters
If you strip away the buzzwords, the basic principles are straightforward. First, your trust boundary moves from “my server” to “my function and its dependencies” plus all the managed services it touches. That means identity and permissions become your primary shield; every function call, event trigger and API integration must be treated as a potential entry point. Second, because functions are short‑lived, you lean less on host hardening and more on configuration correctness, dependency hygiene, and robust observability. Third, you must assume your cloud provider will protect the underlying platform, but everything above the runtime line — code, configs, data flows, secrets — is on you. When people look for melhores práticas de segurança para aplicações serverless, they’re really asking how to operationalize these ideas: least privilege everywhere, minimal attack surface in code and infrastructure-as-code, and continuous feedback loops so misconfigurations don’t stay hidden for months.
Main risks and real‑world attack patterns in serverless
In practice, attackers don’t care that your stack is “modern” — they care about the easiest weak spot. For serverless, that often means overly permissive roles, exposed event sources, and vulnerable dependencies. A common pattern is abusing a front‑door API (HTTP, queue, or event bus) to trigger a function with unexpected payloads or rates, leading to injection, data exfiltration or denial of wallet via cost explosion. Another route is compromising a developer laptop or CI pipeline to alter infrastructure templates, quietly granting a function broad access to data stores. Because functions scale automatically, a compromised function can fan out quickly, touching many resources before anyone notices. Supply chain issues are another big one: a single vulnerable library bundled into multiple functions can give an attacker a consistent foothold. Finally, event‑driven chaining can hide the real blast radius — a seemingly harmless function might pass tainted input to another internal function that holds powerful credentials, turning a small bug into a full account‑level incident.
Practical mitigation: turning principles into concrete actions
Talking about risk only helps if it leads to practical controls. Day to day, serverless security is a lot about shaping the environment so the easy mistakes are impossible. Start with identities: each function should have its own role with the narrowest possible IAM permissions, ideally generated from actual usage or from explicit access maps. Then tackle secrets: use managed secret stores and short‑lived credentials, never environment variables with long‑term keys. Next, embed security checks into your build pipeline so that dependencies, IaC templates, and configurations are scanned before deployment. To keep things approachable for developers, wrap these controls in simple defaults: templates, reusable modules, and lint rules they don’t have to think about. This is where ferramentas de segurança para arquitetura serverless matter most — not as shiny dashboards, but as guardrails that run automatically in CI/CD and production, raising focused, actionable alerts rather than generic noise.
Step‑by‑step guide: hardening AWS Lambda in practice
When people ask como proteger funções lambda aws segurança in a concrete way, it helps to walk through a minimal yet realistic baseline. Consider this pragmatic order of operations:
1. Start with IAM:
Define one role per function, granting only the exact actions needed on specific resources. Use conditions (like source ARN) to limit who can invoke the function.
2. Lock down triggers and inputs:
For API Gateway, enforce authentication (JWT, Cognito, custom authorizers) and input validation schemas. For queues and topics, restrict who can send messages and sanitize payloads before processing.
3. Protect data and secrets:
Store credentials and sensitive config in AWS Secrets Manager or Parameter Store with KMS encryption. Load them at runtime as needed, and rotate regularly.
4. Manage the software supply chain:
Pin dependency versions, use private package registries when possible, and run SCA (software composition analysis) in CI to catch known vulnerabilities before deployment.
5. Observe and respond:
Enable centralized logging, integrate CloudWatch logs with a SIEM or log analytics platform, and create alerts for anomalies such as spikes in invocations, errors, or unauthorized access attempts.
Following a disciplined checklist like this doesn’t cover every scenario, but it dramatically reduces the attack surface and turns vague concerns into repeatable engineering work.
Examples of implementation in real teams
Imagine a small fintech building a transaction‑scoring backend entirely on serverless. Initially, all scoring functions share one powerful IAM role, have no explicit schema validation, and log full payloads, including partial card data. After a security review, the team carves the system into more granular functions, each with scoped permissions only to the data they truly need. They introduce a shared validation library to enforce strict JSON schemas at the edges, ensuring only sanitized fields flow into internal logic. Secrets move from environment variables into a managed store, and logs are scrubbed to avoid sensitive content. On the observability side, they wire function logs and metrics into a central dashboard and define specific alerts around unusual error codes or high‑cost spikes. The shift doesn’t make them invincible, but it turns vague worry into a set of explicit, testable guarantees — and it does so without killing delivery speed, which is exactly what good segurança serverless na nuvem should look like in the real world.
Tools that actually help instead of adding noise
In the serverless ecosystem, tools can be either a force multiplier or a distraction. The ones that tend to work well focus on a few clear jobs: scanning infrastructure‑as‑code templates for risky defaults, analyzing IAM policies for over‑privilege, checking dependencies for known vulnerabilities, and correlating function logs and metrics to detect suspicious patterns. Instead of wiring in half a dozen overlapping products, it’s usually smarter to pick a small set that integrates directly with your CI/CD pipeline and your existing observability stack. For example, IaC scanners can block merges if a function gets wildcard permissions, while SCA tools fail the build on critical vulnerabilities. Log analysis platforms can trace a request across multiple functions, helping you see the full blast radius of an anomalous call. By treating ferramentas de segurança para arquitetura serverless as part of the engineering toolkit — alongside linters and test runners — you keep friction low and make secure behavior the path of least resistance.
Common misconceptions that slow teams down
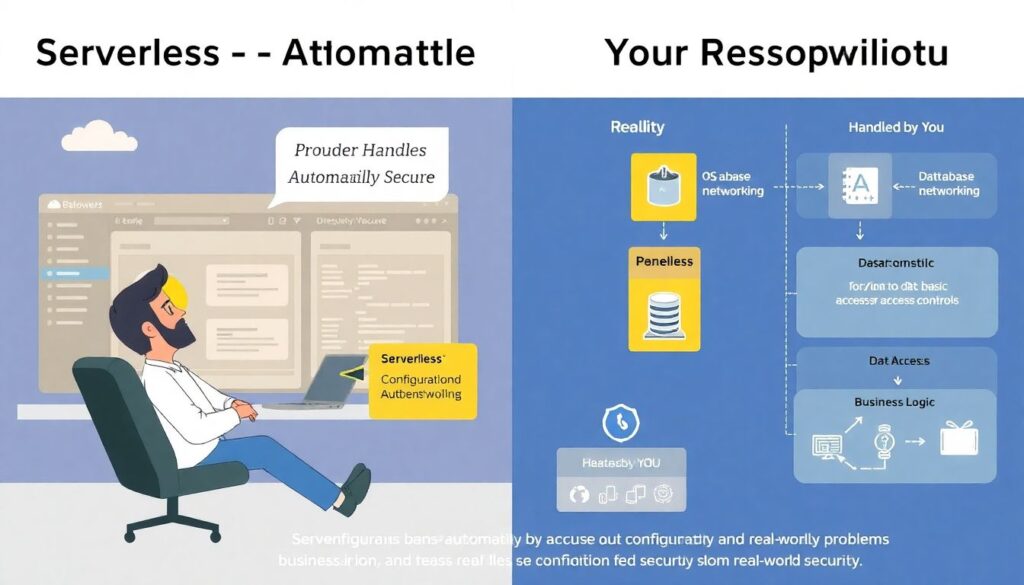
A few myths crop up repeatedly and cause real‑world trouble. One is the belief that “serverless is automatically secure because the provider handles everything.” The provider does handle the OS and much of the networking, but configuration, data access, and business logic are fully your responsibility. Another misconception is that small functions are inherently safer; in reality, many tiny functions with messy permissions and unknown dependencies can be harder to reason about than a well‑structured monolith. There’s also the idea that cost‑based protections will naturally prevent abuse, yet attackers frequently exploit generous default limits or under‑monitored background jobs to run large‑scale operations cheaply. Finally, some teams assume that traditional perimeter defenses — WAFs, network ACLs — are enough, forgetting that event sources like queues, buckets or schedulers bypass classic HTTP entry points. Surfacing these misunderstandings explicitly helps when you’re defining melhores práticas de segurança para aplicações serverless in your organization, because you can design guidelines that counter the myths directly.
When to call in outside expertise
Not every company needs a full‑time serverless security specialist, but almost every team hits a point where ad‑hoc knowledge is no longer enough. Typical signs include growing numbers of functions with unclear ownership, repeated configuration mistakes, or audits revealing inconsistent access controls. At that stage, bringing in consultoria segurança serverless para empresas can accelerate learning and help you avoid painful missteps. The most useful external partners don’t just deliver a slide deck; they sit with your developers, look at your CI/CD pipeline, threat‑model key workflows, and co‑create playbooks for secure deployments and incident response. After that foundation is in place, your internal teams can iterate confidently, knowing that security is woven into architecture and process, not bolted on at the end. Over time, this combination of practical guidance, automation, and continuous feedback is what turns serverless from a security worry into an operational advantage.