Why hardening managed Kubernetes is non‑negotiable in production
If you run workloads on EKS, AKS or GKE and still think “the cloud provider takes care of security”, you’re betting your production on a misunderstanding. Managed control planes are a huge advantage, but they don’t magically give you the melhor configuração de segurança kubernetes gerenciado eks aks gke. The shared responsibility model leaves a wide surface area in your lap: networking, identities, workloads, policies, secrets, and the way your teams actually operate the platform every day. Hardening Kubernetes EKS AKS GKE produção is less about fancy tools and more about a disciplined baseline that you can automate, audit and evolve without blocking delivery.
Mindset first: from “it works” to “it resists attacks”
Before talking about pod security standards or network policies, the hardest shift is cultural. Many teams proudly say “we deployed to Kubernetes in two weeks”, and they did — but with default security settings, cluster‑admin bound to CI, public load balancers open to the world and images pulled from random Docker Hub accounts. Hardening is the decision to treat your cluster as hostile by default: assume leaked credentials, vulnerable dependencies and misconfigured apps will happen, and design so that one mistake does not become a full‑cluster compromise. When you anchor your work on boas práticas hardening cluster kubernetes em produção, velocity becomes a function of safety, not its opposite.
The minimal production baseline: what “good enough” really means
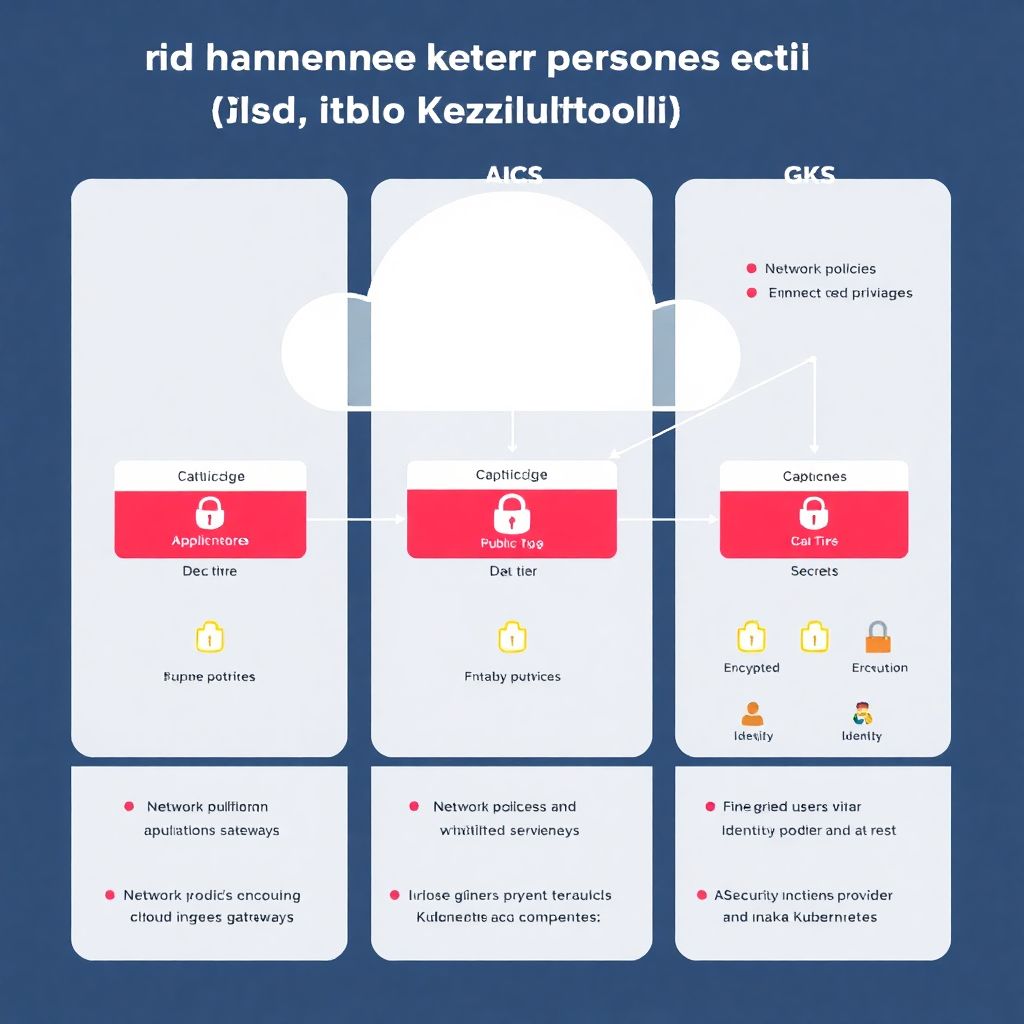
Let’s build a pragmatic “floor”, not a fantasy “ceiling”. The idea of a configuration mínima recomendada is that a new cluster can go live only when certain controls are in place and tested. This is your living checklist segurança kubernetes eks aks gke, not a one‑time compliance document. At this baseline you should have: isolated networks, workload identities instead of node privileges, encryption at rest and in transit, strong policies on what runs where, and a clear trace from user or service to every action in the cluster. From there you can iterate into more advanced controls like zero‑trust networking or eBPF‑based runtime defense.
Networking: don’t trust the flat cluster
Most real‑world incidents in managed Kubernetes start with over‑permissive networking. One compromised pod talks to internal admin services, or a staging cluster reaches production databases “temporarily”. To get closer to the melhor configuração de segurança kubernetes gerenciado eks aks gke, treat your Kubernetes networking like you would treat a data center with strict zones: public edge, app tier, data tier, and privileged platform components. Even if EKS, AKS and GKE simplify load balancers and node networking, you still define which pods may talk to what, and from which external CIDRs ingress is allowed.
Key recommendations for a minimal but serious network posture:
– Use private clusters where possible: control plane with private endpoint, nodes without public IPs; expose only ingress gateways or specific services through managed load balancers.
– Enforce Kubernetes NetworkPolicies in all namespaces, starting with a “deny by default” approach and then whitelisting required flows between apps, system components and external services.
– Segment environments at the VPC/VNet level: separate network stacks for dev, staging and production, with explicit, audited connectivity rules rather than “flat” shared networks.
Identity and access: granular RBAC or nothing
The quickest way to turn a solid cloud provider into a liability is to blur identities. Shared kubeconfig files, cluster‑admin for the entire DevOps team, CI using admin tokens “because it’s easier” — all of these are time bombs. When you think about como proteger ambiente kubernetes gerenciado na nuvem, your first defense is always who can do what, from where, and using which mechanism. Tie Kubernetes, cloud IAM and workload identities together so that humans and services get only the precise permissions they need, bounded in time and observed by logs.
A robust minimal posture for IAM and RBAC in EKS, AKS, GKE includes:
– Integrate clusters with an IdP (Azure AD, AWS IAM Identity Center, Google Cloud Identity, Okta, etc.) and disable static “forever” kubeconfigs for humans.
– Use role‑based access control with scoped Roles and RoleBindings per namespace; reserve ClusterRoles for platform teams and cluster‑level automation only.
– Map service accounts to cloud roles (IRSA in EKS, Workload Identity in GKE, Managed Identities for AKS) so pods never need generic node credentials or long‑lived keys.
Workload and image hardening: don’t trust your containers
Even if the cluster is locked down, your workloads bring in their own risk: vulnerable base images, debug capabilities left enabled, containers running as root. Hardening kubernetes eks aks gke produção requires making secure container configurations the default rather than a “nice‑to‑have”. When you standardize on hardened base images, least‑privilege container permissions and automated scanning, you reduce the blast radius of inevitable application bugs. A good rule of thumb is: assume any pod can be broken into; your job is to make that breach boring and contained.
Essential workload‑level practices for production:
– Enforce Pod Security Standards or PodSecurityPolicies alternatives (where applicable) so containers don’t run as root, cannot escalate privileges and mount sensitive host paths.
– Sign and scan container images (Snyk, Trivy, Clair, native cloud tools) and block deployments of images with critical vulnerabilities or coming from untrusted registries.
– Use resource requests/limits, read‑only root filesystems, non‑root users and capabilities dropped by default, then grant narrowly when needed.
Real‑world case 1: a fintech that refused to “rebuild everything”
A mid‑size fintech in Latin America migrated its core payment services to GKE with tight product deadlines. The first clusters went live fast, but “temporary” shortcuts accumulated: developers with cluster‑admin access, shared namespaces between services, a single VPC for all environments, and CI pipelines using static admin tokens. An internal red‑team exercise later showed that a SSRF vulnerability in a low‑risk microservice could be chained into access to production secrets and even the cluster’s metadata API. The findings were a wake‑up call, but the team didn’t have the appetite for a complete redesign. Instead, they introduced a staged hardening program that respected delivery goals.
They started by defining a minimal baseline for all new namespaces: enforced NetworkPolicies, dedicated service accounts mapped to Workload Identity, Pod Security Standards in “enforce” mode and required labels for ownership and environment. Legacy workloads were gradually moved into this pattern behind a compatibility layer. Within six months, they reduced direct cluster‑admin users from 40 to 3, isolated staging from production at the network level, and removed all long‑lived tokens from CI. Incidents related to misconfigurations dropped sharply, and an external audit later highlighted their boas práticas hardening cluster kubernetes em produção as a strength in their compliance posture.
Real‑world case 2: media company scaling EKS without losing control
A large media platform adopted EKS to handle traffic spikes during live events. The initial architecture was sensible: private nodes, ALB ingress, and separate clusters per environment. Over time, though, each team tweaked settings independently. Some workloads used their own Docker Hub images, others bypassed security scans “temporarily”, and cluster add‑ons were installed by whoever needed them. When they began preparing for ISO 27001 certification, they realized they had no consistent view of their security baseline and no shared operating model. The risk was not a single catastrophic vulnerability but death by a thousand exceptions.
They decided to standardize on a golden‑path “platform cluster” configuration. Platform engineers built a Terraform module and GitOps templates that encoded their minimal hardening decisions: private EKS cluster, IRSA for all workloads, mandatory namespace isolation, standard logging/monitoring stack and predefined RBAC roles mapped to AWS IAM groups. Application teams onboarded gradually, but with strong incentives: the platform path gave them autoscaling, observability and faster reviews, while “custom” clusters required security approval. In less than a year, 80% of production workloads migrated to the hardened path, and they could finally describe the melhor configuração de segurança kubernetes gerenciado eks aks gke as implemented code rather than a slide in a presentation.
Real‑world case 3: AKS, healthcare data and zero public exposure
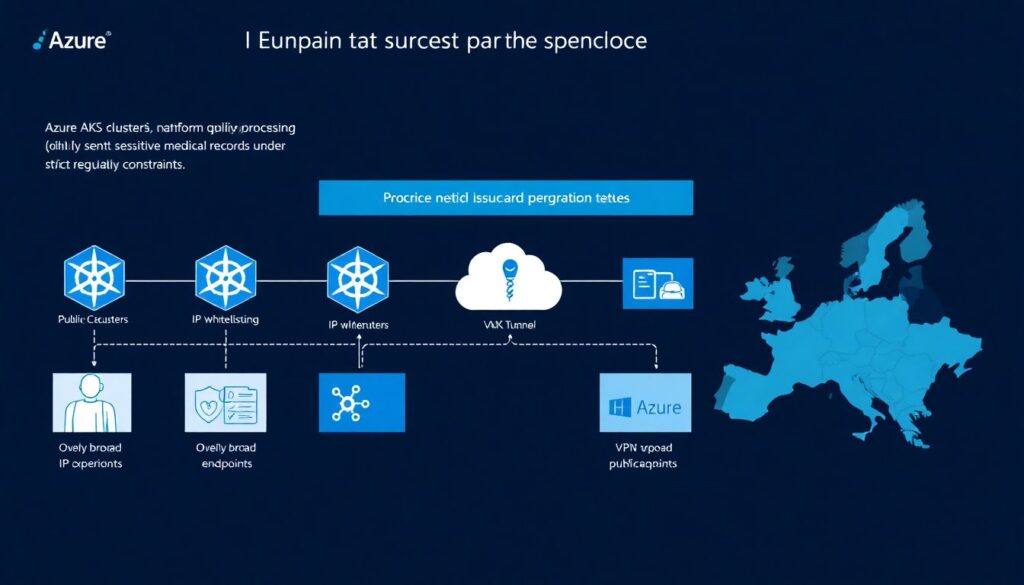
A healthcare analytics startup in Europe built their platform on AKS, processing sensitive medical records with strict regulatory constraints. The early architecture used public clusters with IP whitelisting for operators and a VPN into the VNet. A pentest revealed flaws: IP whitelists were too broad, Bastion hosts were misconfigured, and some data‑processing pods could reach the public internet without reason. Faced with an upcoming customer security review, they needed a story on como proteger ambiente kubernetes gerenciado na nuvem that aligned with healthcare‑grade expectations.
They moved to a private AKS cluster, dropped public IPs on nodes, and routed all operator access through a hardened jump environment and Azure AD‑integrated kubectl. NetworkPolicies were applied aggressively: only ingress gateways could accept external traffic, data‑processing workloads could talk solely to storage endpoints and message brokers, and egress to the internet was blocked by default at the NSG level. They coupled this with pod identity using Managed Identities and encrypted volumes for persistent data. Within three months, the next pentest found only minor issues, and a major hospital group approved them as a vendor, explicitly citing their Kubernetes hardening strategy as a differentiator.
From baseline to excellence: how to keep evolving
A static checklist is not enough when threats, features and your own architecture keep changing. The teams in the stories above succeeded because they turned their baseline into a living practice: every new cluster, namespace or application followed the same opinionated defaults, and every new lesson from incidents or audits fed back into those templates. Over time you move from “we hardened once” to “we continuously refine our guardrails”. A practical way to approach this is to treat your hardening as a product: it has users (developers), a roadmap, versioning and feedback loops, not just policy docs nobody reads.
Useful habits to evolve your hardening practice:
– Codify everything: clusters, IAM bindings, policies, logging, network rules, and even default Pod specs should live in version‑controlled IaC and GitOps repos.
– Run continuous security scans (CIS benchmarks, kube‑bench, cloud‑native scanners) and fold findings into sprints; treat them as tech debt, not optional “security tasks”.
– Embrace blameless post‑mortems for security near‑misses, extracting platform improvements and better defaults rather than hunting for individual mistakes.
Learning resources to accelerate your journey
You don’t need to reinvent hardening from scratch. There is a mature body of knowledge around managed Kubernetes security — the real challenge is filtering noise and aligning guidance with your context. Focus on materials that combine vendor‑agnostic principles with EKS, AKS and GKE specifics, and always test advice in non‑production clusters before standardizing. Over time, build an internal knowledge base linking these external sources to your own playbooks, diagrams and code examples so new engineers learn your way, not just “generic Kubernetes”.
Some starting points worth investing time into:
– CNCF and Kubernetes docs: security concepts, Pod Security Standards, NetworkPolicies, admission controllers, RBAC patterns, and the official hardening guide.
– Cloud‑specific security baselines: AWS EKS Best Practices Guide, Azure AKS baseline reference architectures, Google’s GKE hardening and security posture docs.
– Hands‑on labs and CTFs focused on Kubernetes: they build intuition about misconfigurations and attacks far better than slide decks or theoretical courses.
Bringing it all together
Hardening Kubernetes in managed environments is not about paranoia; it’s about respect for your users, your data and your future self on call at 3 a.m. A minimal but serious baseline for EKS, AKS and GKE — covering network isolation, identity, workload constraints, observability and automation — turns chaotic clusters into reliable infrastructure. The inspiring part is that this is attainable for small teams as well: start with a single hardened cluster, encode it as code, then replicate and refine. With a clear baseline, real‑world feedback and continuous learning, hardening kubernetes eks aks gke produção stops being a scary buzzword and becomes the everyday way you build and run systems in the cloud.