Why serverless APIs need extra love
Running APIs on Lambda, Cloud Functions or Azure Functions feels magical: no servers, auto‑scaling, pay‑per‑use. But that magic hides sharp edges. In serverless, cold starts, ephemeral instances and heavy use of managed services completely change how you think about threat models, observability and performance. Security incidents travel faster because scaling is automatic, and debugging is harder because you don’t “SSH into a box”. So “segurança de apis serverless aws” is not just about toggling a WAF; it’s about designing every lambda invocation as if it were exposed to the internet on its own.
—
Quick mental model of a serverless API
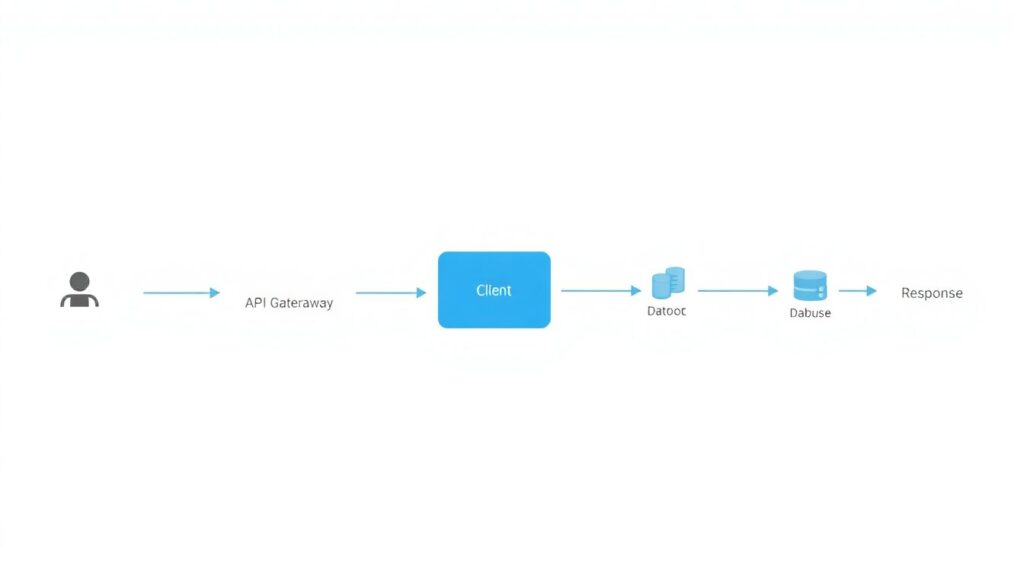
Before diving into authentication, rate limiting and logging, align on what “serverless API” actually is. Think of this basic flow:
[Diagram: Client → API Gateway → Authorizer → Lambda → DB / Queues / Other services → Response]
In words: API Gateway handles HTTP, runs an authorizer (JWT, Lambda Authorizer or IAM), forwards the request to a function, which talks to data stores or queues. Each of these hops is a security boundary. Unlike monoliths, there’s no single always‑on process; every call is a fresh execution context. That’s awesome for isolation, but it means you must re‑establish trust (auth, policy, quotas, logging) on every request, not “once per process”.
—
Authentication: defining who is talking to you
Authentication is simply “who is this caller, really?”. In serverless APIs that usually means one of three options: public JWTs (Cognito, Auth0, Keycloak), signed requests (AWS SigV4, service accounts) or API keys. For human users, JWTs win: stateless, cacheable, easy to validate in API Gateway. For service‑to‑service traffic, IAM or mTLS is safer than sharing secrets. API keys should be treated as coarse‑grained identifiers, not as strong auth. When people talk about “melhores práticas de autenticação e autorização em apis serverless”, they mostly mean: don’t put custom crypto in Lambdas, and terminate identity at the edge.
—
Non‑obvious auth trick: push logic out of the function
A common anti‑pattern is verifying tokens inside the Lambda handler every time. That burns CPU, adds latency and spreads security logic all over your code. Instead, move heavy auth to API Gateway or a custom Lambda Authorizer. The diagram becomes:
[Diagram: Client → API Gateway → (Custom Authorizer: validate JWT, load roles) → Lambda (trusted claims in headers)]
This way, the function receives already‑validated claims, such as `x-user-id` and `x-tenant-id`. You gain two wins: smaller handlers and centralized security. As a bonus, you can reuse the same authorizer across dozens of routes and even across services, so a bug fix or a new rule instantly applies everywhere.
—
Authorization: what is this caller allowed to do?
If auth is “who you are”, authorization is “what you can do”. In serverless this is tricky, because you often combine user‑level rules (RBAC, ABAC, multi‑tenant boundaries) with cloud‑level policies (IAM, roles, resource policies). A solid pattern is to define three layers: edge policies in API Gateway, fine‑grained rules inside the function and least‑privilege IAM for downstream resources. Compare it with a classic monolith, where everything runs as one OS user hitting the DB with a single fat account; serverless lets you slice permissions per function, per route, even per tenant, if you want to get fancy.
—
Unusual idea: “policy as data” instead of hard‑coding checks
Standard advice is “check roles in code”: `if (!user.roles.includes(‘admin’)) throw`. It works but becomes unmanageable at scale. A more flexible approach is “policy as data”: store JSON or Rego policies per tenant or per feature flag, load them cheaply (e.g., via Lambda Extensions or in‑memory cache with TTL) and evaluate on each request. Your deployment no longer changes when business rules change. This is especially powerful for B2B multi‑tenant APIs, where each customer wants custom rules. You effectively ship a generic engine, while your auth behavior is configuration.
—
Rate limiting: controlling how hard people can hit you
Rate limiting answers a simple question: “How many requests per unit of time will we tolerate from this identity, IP or token?”. In serverless, over‑aggressive clients don’t just slow your servers; they increase your cloud bill and can trigger cold start storms. That’s why “ferramentas de rate limiting para apis serverless” are more than comfort features; they’re bill‑protection and DDoS‑mitigation tools. Classic token‑bucket per node doesn’t work well because you don’t control nodes; instead, centralize quotas at the edge (API Gateway, CloudFront, service mesh) or use distributed stores like Redis and DynamoDB.
—
Non‑standard rate limiting: shape traffic instead of just blocking
Instead of a simple “HTTP 429 when quota exceeded”, consider traffic shaping. For example, for non‑critical endpoints you can queue excess requests via SQS or Pub/Sub and process them later, returning a “202 Accepted” immediately. For write‑heavy operations, you can degrade gracefully: allow reads but throttle writes, or temporarily lower per‑user limits while keeping global limits high. Another trick: dynamic limits driven by fraud signals. If your anomaly detection flags a suspicious client, cut its rate caps in real time, without pushing code. Rate limiting becomes an adaptive perimeter, not a static ceiling.
—
Secure API Gateway as the real front door
When people google “como proteger api gateway em arquitetura serverless”, they often underestimate how powerful the gateway already is. You can enforce TLS, mutual TLS, WAF rules, IP allow/deny lists, JWT validation, throttling and request/response size limits all before your Lambda runs. Think of the gateway as your “mini reverse proxy firewall”. Compared with classic Nginx or HAProxy stacks, you don’t manage instances or config reloads; you push a new config and the provider rolls it out globally. The downside is vendor‑specific quirks, so hide those behind a clean internal API contract.
—
Diagram: layered defenses around your API
[Diagram:
Internet → CDN / WAF (IP blocking, geo rules, basic bot filters)
→ API Gateway (TLS/mTLS, JWT verification, rate limits, schema validation)
→ Authorizer (custom logic, tenant routing, fine‑grained scopes)
→ Lambda (business logic with minimal security surface)
→ Data plane (DB, queues, event buses with strict IAM)
]
Each ring rejects bad traffic as early as possible. The function should see only well‑formed, authenticated, rate‑limited requests, making the handler’s job mostly business logic and fine‑grained authorization, not survival.
—
Logging and monitoring: your only window into production
Because serverless is so ephemeral, “just check the logs on the box” is impossible. That makes “monitoramento e logging de apis serverless em produção” absolutely central. Aim for three layers of observability: structured logs, metrics and traces. Logs should be JSON with correlation IDs, tenant IDs and user IDs where legal. Metrics need business signals (orders per minute, failed logins) and technical ones (latency, errors, cold starts). Traces tie it together across services. Compared with traditional VMs, you log less noise but more context, because each invocation is a discrete unit of work.
—
Weird but useful logging patterns
Two unconventional but effective ideas. First, “negative sampling”: by default, don’t log every success in detail; log every error fully, and then probabilistically sample, for example, 1% of successful requests for deep logging. This keeps costs sane while still giving insight into the happy path. Second, maintain a “security trail” channel: a dedicated sink (e.g., separate log group or index) for auth events, permission denials and rate limit hits. Security teams can wire alerts on that channel without sifting through business logs, enabling much faster incident triage.
—
Tying it all together on AWS
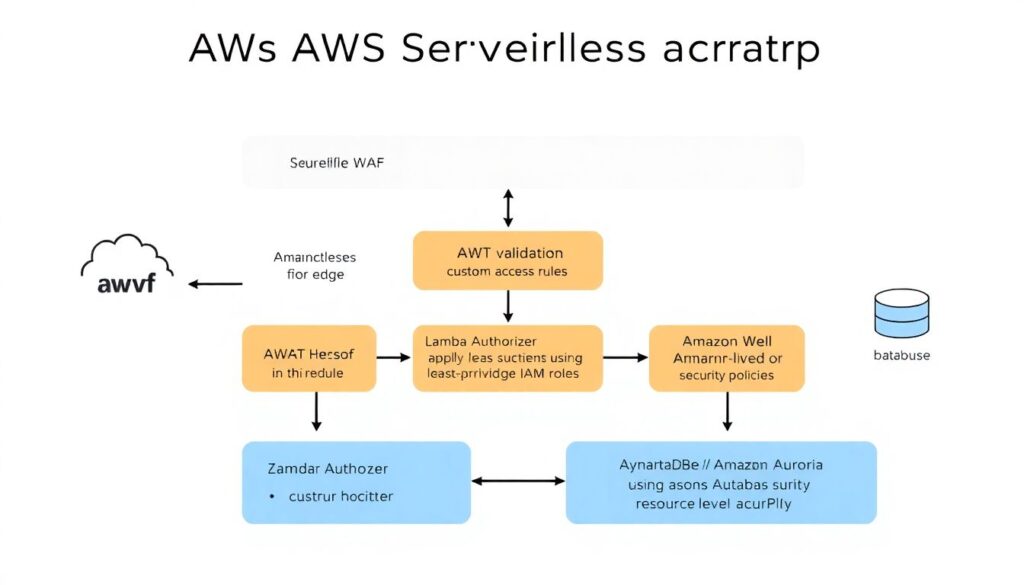
If you’re on AWS, a secure baseline for segurança de apis serverless aws might look like this: CloudFront + WAF at the edge, API Gateway with JWT validation and throttling, Lambda Authorizer for custom rules, Lambdas with least‑privilege IAM roles, DynamoDB or Aurora with resource‑level policies and CloudTrail plus CloudWatch/Prometheus for audit and metrics. Then layer on feature flags for authorization policies, and use Step Functions or queues to absorb spikes instead of letting bursty traffic slam your functions directly. The end result: an API that scales fast but fails gracefully and predictably.
—
Final thoughts: design for failure and abuse from day one
Secure serverless APIs aren’t about sprinkling security features after you write handlers. They come from modeling abuse cases early: stolen tokens, noisy clients, buggy integrations, angry tenants. If you bake in strong authentication, explicit authorization, adaptive rate limiting and rich logging before launch, most incidents become noisy but harmless instead of catastrophic. With these melhores práticas de autenticação e autorização em apis serverless in place, you can confidently lean into the advantages of serverless—cheap, elastic, low‑ops—without turning your API into an unmonitored money‑burning firehose.