Serverless começou como aquela “camada mágica” onde você só escreve função e o resto a nuvem resolve. Mas, quando o assunto é segurança, a magia some rápido. De repente aparecem perguntas chatas: quem pode invocar essa função? Onde estão os segredos? Como impedir que uma função comprometida ataque o resto do ambiente? Neste texto, vamos olhar para ameaças reais, controles que de fato funcionam e padrões de arquitetura que ajudam a manter a proteção de workloads serverless na nuvem sem matar a agilidade do time de produto. A ideia é misturar teoria com histórias de campo, do tipo “aprendemos do jeito difícil, mas aprendemos”.
Ameaças típicas em workloads serverless
O modelo serverless muda a superfície de ataque. Você quase não fala mais de patch de sistema operacional, mas precisa se preocupar muito mais com permissões granulares, eventos maliciosos e dependências de terceiros. Uma função aparentemente inocente, disparada por um upload em bucket, pode virar ponto de entrada para exfiltração de dados ou para movimentos laterais usando credenciais excessivamente permissivas. Outro clássico: funções expostas via API Gateway sem proteção adequada contra injection, rate limiting fraco e logs incompletos. Em ambientes modernos, a segurança em aplicações serverless depende muito do desenho dos eventos e da forma como o código lida com entradas externas e secretos.
De forma prática, as três categorias de risco que mais aparecem em incidentes são: exposição indevida de endpoints, permissões IAM “largas demais” e bibliotecas vulneráveis. Não é glamouroso, mas é o que derruba sistemas.
Casos reais: o que quebra na vida real
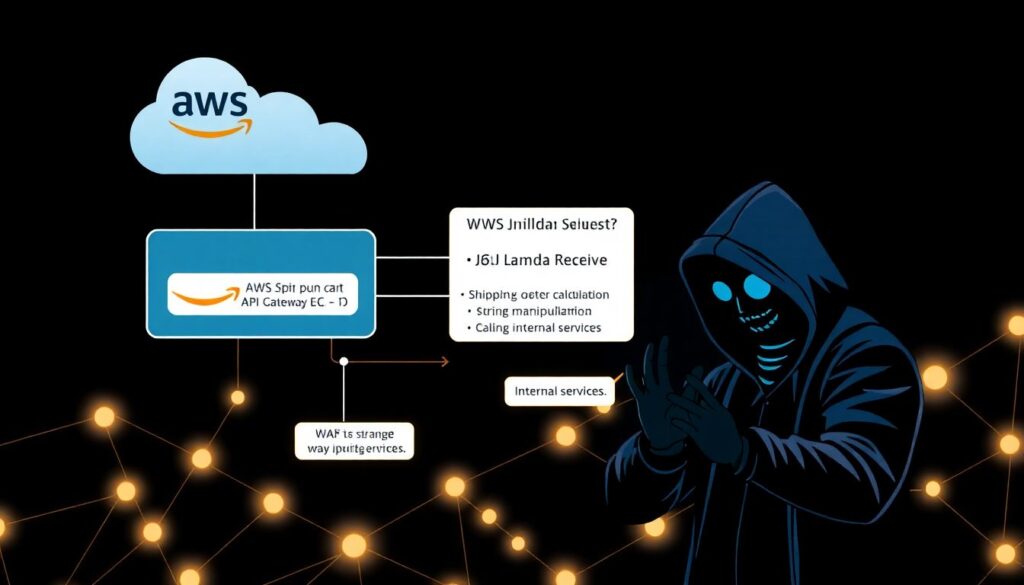
Num e‑commerce de médio porte rodando em AWS Lambda, o time confiava no WAF em frente ao API Gateway e achava que estava tudo bem. Uma função de cálculo de frete recebia um JSON, manipulava strings e chamava serviços internos. Um invasor começou a testar inputs estranhos e descobriu um caminho para injeção de comando em uma biblioteca de imagem usada em outra parte do fluxo. A função tinha permissão para ler vários buckets “por conveniência”. Resultado: acesso indevido a relatórios de vendas e dados sensíveis. O problema não era só o bug na lib, mas a ausência de princípio de menor privilégio e a falta de segmentação entre funções de front e funções com dados críticos.
Em outro contexto, uma fintech em Azure Functions sofreu com negação de serviço indireta. Um cliente mal‑intencionado disparava chamadas baratas, mas que geravam fan‑out para dezenas de funções downstream. A conta de cloud disparou, alarmes de performance tocaram, e o time percebeu que não havia limites de concorrência bem definidos nem filas intermediárias para absorver picos. Não foi uma falha de criptografia ou autenticação; foi um desenho de fluxo que facilitava abuso econômico da plataforma.
Controles essenciais para funções e eventos
Identidade, acesso e segredos
O alicerce de qualquer arquitetura serverless segura é um modelo de identidade e acesso muito mais disciplinado do que no mundo de VMs. Cada função deve ter um papel específico, com permissões minimamente necessárias, em vez de compartilhar um único role “superpoderoso” por ambiente. O uso de cofres de segredos gerenciados (como AWS Secrets Manager ou Azure Key Vault) é obrigatório, não opcional, para evitar credenciais em variáveis de ambiente estáticas ou, pior, dentro do código. As ferramentas de segurança para funções serverless mais modernas integram scanners de IAM, análise de política e checagem de uso real de permissões, ajudando a reduzir privilégios com base em dados. Quanto mais você automatiza essa revisão, menos depende de “boa vontade” do time de desenvolvimento.
Em resumo: trate roles como código, segredos como ativos de alto valor e qualquer acesso extra como débito técnico de segurança.
Case: limpando o IAM sem parar o time
Um time de plataforma em uma scale‑up de SaaS percebeu que quase todas as Lambdas usavam uma role chamada “lambda-default-full”. Clássico. Em vez de tentar consertar tudo na marra, eles começaram registrando o uso real de permissões via logs de acesso por 30 dias. Depois, geraram políticas mínimas baseadas em uso e revisaram apenas as funções mais críticas de cada domínio. Na sequência, fizeram um playbook: nova função só vai para produção se tiver role dedicada e revisada. Em seis meses, reduziram mais de 70% das permissões desnecessárias sem bloquear o fluxo de entrega. O ponto chave foi tratar IAM como parte do ciclo de desenvolvimento, e não como auditoria de fim de ano.
Observabilidade, logs e resposta
Sem visibilidade, nenhum controle funciona. Em ambiente serverless, logs aparecem espalhados entre serviços de nuvem, APIs gerenciadas e sistemas de fila. É essencial consolidar métricas, logs de aplicação e trilhas de auditoria em um único lugar para correlação. Isso não é só questão de troubleshooting, mas base para detecção de anomalias: picos de invocação, erros de autenticação, acessos incomuns a recursos internos. Para apoiar as melhores práticas de arquitetura serverless segura, muitos times adotam padrões como “tudo que chega pela borda é logado com contexto mínimo”, “toda chamada a recursos sensíveis emite um evento de segurança” e “falhas suspeitas disparam alertas automatizados”. Essa disciplina transforma funções isoladas em um sistema observável, onde incidentes não passam despercebidos por semanas.
E quando algo der errado, scripts prontos de resposta (revogar chaves, limitar concorrência, pausar triggers) valem ouro.
Padrões de arquitetura segura: do diagrama ao código
Segmentação, eventos e malha de serviços
Uma arquitetura serverless robusta começa desenhando fronteiras claras. Funções voltadas para a internet devem ser finas, limitando‑se a validação, autenticação e roteamento, delegando lógica sensível a funções internas expostas apenas por eventos ou filas. Esse “strangling” da superfície de ataque reduz drasticamente o impacto de vulnerabilidades típicas de API. Ao mesmo tempo, é fundamental orquestrar eventos através de filas, tópicos e orquestradores que permitam aplicar limites de taxa e de concorrência, evitando o efeito dominó de um pico inesperado. Quando falamos de proteção de workloads serverless na nuvem, muitos incidentes recentes não são sobre invasão clássica, mas sobre abuso de fluxo: sequências de funções encadeadas que amplificam custo, latência ou acesso sem controles intermediários.
Arquiteturas bem segmentadas geralmente parecem mais “chatas” visualmente, com muitas caixinhas, mas se comportam muito melhor sob ataque.
Case: redesenhando uma API de pagamento
Uma empresa de pagamentos digitais tinha uma API única que disparava diretamente várias Lambdas internas, todas com acesso a dados de transações, conciliação e relatórios. Depois de uma simulação de ataque (red team), ficou claro que comprometer essa única API dava alcance demais ao invasor. O redesenho dividiu o fluxo em três camadas: borda pública com funções minimalistas e forte validação, camada de orquestração com filas para cada tipo de operação e camada de funções internas sem exposição direta, com roles extremamente limitadas. O resultado foi menos acoplamento, melhor rastreabilidade e redução do “blast radius” caso alguma chave de API vazasse.
Escolhendo tecnologias e abordagens
Quando falamos em como proteger aplicações serverless na AWS e Azure, surgem duas linhas principais de abordagem. A primeira é confiar o máximo possível em serviços nativos de segurança da nuvem: WAF gerenciado, scans de configuração, políticas de organização, logging centralizado. A segunda é complementar com ferramentas especializadas de terceiros, que fazem desde análise estática de templates IaC até proteção em tempo de execução com detecção de comportamento anômalo. Em paralelo, há um trade‑off entre frameworks de alto nível (que abstraem provider) e uso direto de recursos nativos. Frameworks multi‑cloud trazem portabilidade, mas às vezes escondem detalhes cruciais de segurança ou atrasam o suporte a features novas. Já usar tudo “na unha” do provider dá mais controle fino, ao custo de maior lock‑in e curva de aprendizado.
Na prática, times maduros costumam mesclar: infraestrutura e segurança críticas usando recursos nativos, e camadas mais próximas do negócio usando abstrações.
Prós e contras dos caminhos mais comuns
Abordagem totalmente nativa de um provedor tende a oferecer melhor integração com logs, IAM e ferramentas de compliance, além de reduzir o número de peças em jogo. O lado ruim é o lock‑in forte e a necessidade de dominar a fundo cada serviço. Já a abordagem híbrida, com ferramentas independentes focadas em segurança, costuma oferecer melhor visibilidade multi‑conta e multi‑cloud, motores de política mais poderosos e dashboards mais amigáveis para equipes de risco. Em compensação, adiciona custos e complexidade operacional. A chave está em definir o “núcleo duro” de segurança — identidade, segredos, logging — o mais próximo possível da infraestrutura nativa e, em seguida, usar soluções externas para enriquecer detecção, correlação e governança.
Tendências até 2026: para onde a segurança serverless está indo
Automação, política como código e IA
Olhando para os movimentos até 2024 e projetando os próximos anos, a segurança de serverless está caminhando para ser cada vez mais declarativa e automatizada. Políticas como código já são padrão em muitas empresas, definindo o que pode ou não ser criado em termos de funções, roles e triggers; esse modelo tende a se aprofundar, com guardrails mais sofisticados rodando em pipelines de CI/CD. Ferramentas baseadas em machine learning começam a analisar padrões de invocação para detectar anomalias sutis que passam batido pelos alertas tradicionais. Ao mesmo tempo, cresce o interesse por “zero trust” aplicado a eventos: cada trigger e cada chamada entre funções exige identidade forte e é avaliado em tempo real. Esses movimentos apontam para um futuro onde o trabalho manual diminui e o foco dos times passa a ser desenhar boas regras, não caçar incidentes um a um.
Nesse cenário, o papel do engenheiro de plataforma é cada vez mais próximo de um “arquiteto de políticas” do que de um administrador de servidores.
Maturidade de padrões e bases de conhecimento
Outra tendência importante é a consolidação de padrões de referência específicos para serverless, indo além de guidelines genéricas de nuvem. Comunidades e vendors estão publicando playbooks focados em casos de uso concretos: ingestão de dados em larga escala, APIs públicas de alto volume, processamento de eventos de IoT. Isso ajuda bastante times que precisam de melhores práticas de arquitetura serverless segura sem reinventar a roda a cada projeto. Do ponto de vista organizacional, a responsabilidade por segurança tende a ser mais distribuída: desenvolvedores assumem ownership de controles básicos em código e configuração, enquanto times de segurança fornecem plataformas, políticas e monitoramento. É um equilíbrio delicado, mas essencial para manter velocidade de entrega sem abrir brechas óbvias.
Na prática, as empresas que se destacam em segurança serverless não são as que compram mais ferramentas, e sim as que tratam segurança como parte da própria arquitetura.
Recomendações práticas para começar ou evoluir
Passos concretos, sem paralisar o desenvolvimento
Para quem está começando ou já tem um ambiente em produção, mas sente que a casa está meio improvisada, um caminho pragmático é priorizar três frentes. Primeiro, mapear funções e triggers mais expostos e aplicar rapidamente controles de IAM, autenticação forte e rate limiting — é onde o impacto de um ataque é maior. Segundo, consolidar logging e criar alguns alertas simples, porém eficazes, como picos de invocação por função, aumento súbito de erros 4xx/5xx e acessos incomuns a recursos sensíveis. Terceiro, revisar segredos e tokens, migrando o que for possível para cofres gerenciados e rotacionando chaves antigas. Em paralelo, introduza revisões leves de arquitetura focadas em risco, não em “perfeição”, incorporando esses checks ao fluxo de pull requests.
O objetivo não é chegar a um “estado ideal” definitivo, e sim criar um ciclo contínuo de melhoria, onde cada nova feature nasce um pouco mais segura que a anterior.
Fechando o ciclo: cultura e aprendizado contínuo
Nenhuma pilha de tecnologia substitui uma cultura que leva segurança a sério sem transformar tudo em burocracia. Workshops rápidos de threat modeling focados em flows reais, sessões de revisão de incidentes (inclusive os de outras empresas) e a prática de escrever pequenos RFCs de arquitetura ajudam o time a enxergar riscos antes que eles virem manchete. Em ambientes altamente dinâmicos, como o de serverless, segurança não pode ser apenas checklist de auditoria; precisa ser uma conversa constante entre negócio, desenvolvimento e operações. Quando isso acontece, a segurança em aplicações serverless deixa de ser “trava” e passa a ser parte natural do design, tão essencial quanto performance ou custo. E é aí que a promessa de agilidade da computação serverless realmente se realiza, sem deixar a porta dos fundos aberta.