Por que integrar SIEM e observabilidade em multi cloud não é opcional
Se você já passou do ponto de ter “só um” provedor cloud, provavelmente está naquele cenário caótico em que AWS, Azure e Google Cloud convivem, cada time usa o que quer, e os logs viram um labirinto. Aí alguém fala: “vamos colocar um SIEM e pronto, fica tudo seguro”. Só que não é bem assim. Integrar SIEM com soluções de observabilidade em um ambiente com múltiplos provedores cloud é menos sobre ferramenta e mais sobre disciplina, desenho de arquitetura e decisões chatas (mas essenciais) sobre logs, métricas e traces.
O ponto-chave: segurança e observabilidade não andam separadas em ambiente distribuído. Seu SIEM precisa enxergar o mesmo “filme” que a stack de observabilidade, e esse filme vem dos logs de cada pedacinho da sua infra. Se você só joga tudo em um balde de logs e acha que o SIEM vai “se virar”, você só está empurrando o problema para frente. Integrar direito significa ter contexto, padronização e prioridade definida sobre o que realmente importa monitorar e correlacionar.
Entendendo o quebra‑cabeça: SIEM x observabilidade
Antes de falar de pipeline de logs e erros comuns, vale alinhar expectativa. Um SIEM é focado em segurança: correlação de eventos, detecção de ameaças, investigação de incidentes, resposta. Já as soluções de observabilidade se concentram em saúde de aplicações, performance, experiência do usuário e comportamento do sistema. Em multi cloud, se você tentar fazer tudo só com SIEM, paga caro e sofre; se tentar fazer tudo só com observabilidade, vai ficar cego para ataques mais sofisticados.
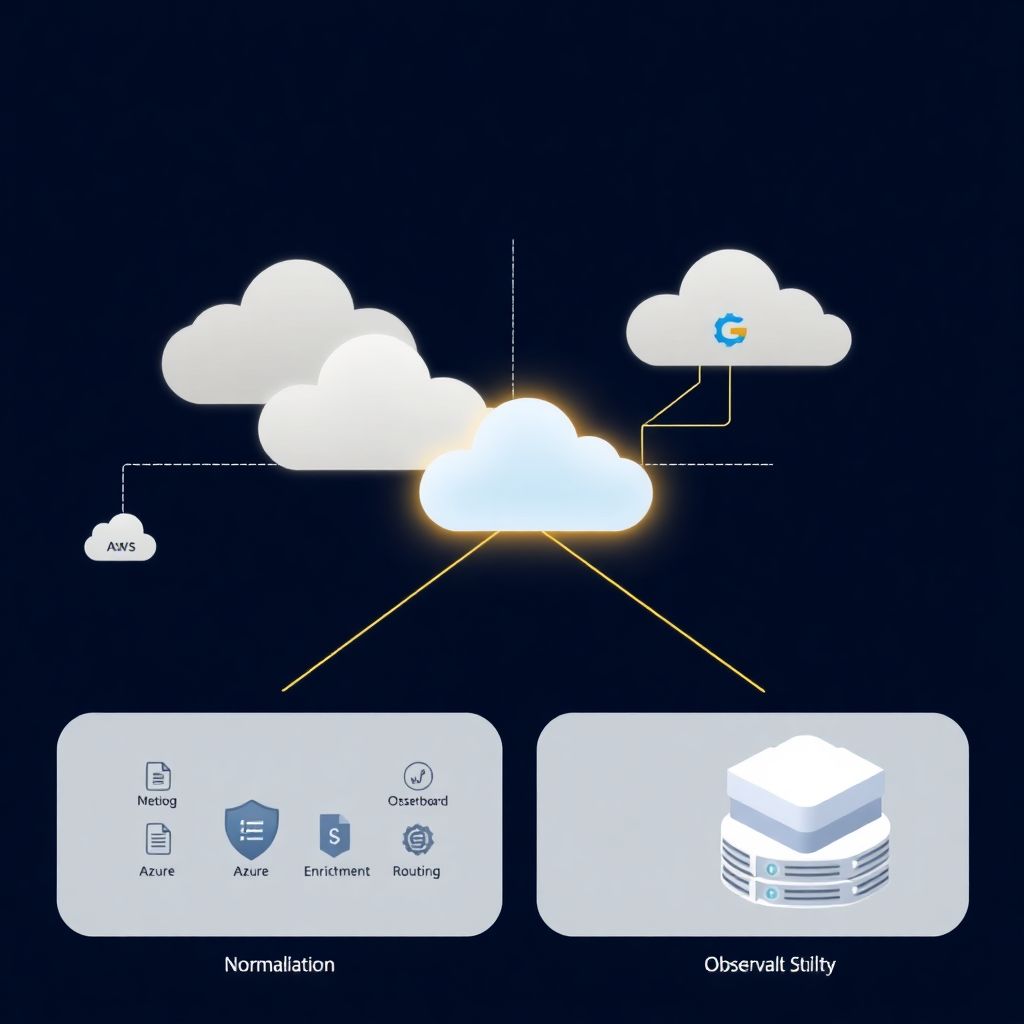
O jogo fica interessante quando você cria uma solução de observabilidade multi cloud com integração de logs que alimenta tanto o seu stack de SRE/DevOps quanto o seu time de segurança. Logs de aplicação, auditoria, rede e identidade trafegam por um pipeline comum, mas com regras claras de enriquecimento, retenção e roteamento. Assim o SIEM não fica sobrecarregado com ruído de performance, e a observabilidade não vira depósito de logs de segurança sem contexto.
Erro #1: Achar que “coletar tudo” resolve
Um dos erros mais comuns de quem está começando é ativar todos os logs possíveis em todas as clouds, mandar tudo para um serviço de centralização de logs em ambiente multi cloud e acreditar que, com isso, ganhou visibilidade. Na prática, você só ganhou conta alta, latência em consultas e uma avalanche de eventos irrelevantes. Mais dado sem estratégia só gera alert fatigue e dificulta achar o que realmente importa.
O caminho mais saudável é desenhar um catálogo de fontes de logs prioritárias. Comece por:
– Logs de autenticação e identidade (IAM, Azure AD, Cloud Identity)
– Logs de firewall, WAF e gateways de API
– Logs de auditoria de configuração (Config, Activity Logs, Admin Activity)
– Logs críticos de aplicação (erros, autenticação, operações sensíveis)
Depois disso, vá adicionando camadas conforme sua maturidade cresce. Não precisa ligar tudo no máximo desde o dia zero.
Erro #2: Ignorar padronização de formatos e campos
Outro tropeço clássico: cada time manda logs para o SIEM em um formato diferente, com campos diferentes, timezones diferentes e nomenclaturas criadas “na hora”. Em uma única consulta você vê `user`, `username`, `user_id`, `subject` e `caller` significando a mesma coisa. Isso mata qualquer correlação multicloud decente, porque sua ferramenta não consegue entender que é tudo o mesmo usuário.
Antes de se empolgar com dashboards, defina um modelo de dados mínimo. Você não precisa reinventar a roda: pode se inspirar em modelos como ECS (Elastic Common Schema) ou similares, mas adapte à sua realidade. O importante é estabelecer:
– Campos padrão para identidade (usuário, conta, tenant)
– Campos de origem (cloud, serviço, região, ambiente)
– Campos de rede (IP de origem/destino, porta, protocolo)
– Campos de severidade e tipo de evento
E, principalmente, documentar isso e fazer parte da “definição de pronto” de qualquer novo serviço que gere logs.
Erro #3: Tratar cada cloud como um planeta isolado
No começo é comum cada squad cuidar “do seu” provedor: time A cuida de AWS, time B de Azure, e assim vai. O problema é quando essa mentalidade se reflete nos logs: pipelines diferentes, padrões diferentes, regras de retenção diferentes. Quando acontece um incidente que atravessa clouds (por exemplo, credencial vazada usada em AWS e depois em Azure), a investigação vira uma gincana.
O ideal é olhar para tudo como um domínio lógico único. Uma boa plataforma de monitoramento e SIEM para AWS Azure e Google Cloud deve ser desenhada para:
– Usar o mesmo pipeline base de ingestão (mesmo se o collector for diferente)
– Aplicar regras comuns de enriquecimento (tags de negócio, dono do serviço, criticidade)
– Padronizar timezones e formatos de timestamp
– Consolidar identidade do usuário entre clouds
Você pode até manter ferramentas nativas para uso local (CloudWatch, Azure Monitor, Cloud Logging), mas sempre com uma camada central onde segurança e observabilidade convergem.
Como desenhar o fluxo de logs sem se perder
Vamos simplificar o fluxo típico. Em cada cloud você tem serviços mandando logs para o mecanismo nativo (por exemplo, CloudWatch, Log Analytics, Cloud Logging). A partir daí, você cria conectores ou agentes que exportam esses logs para um barramento comum de ingestão (por exemplo, Kafka, um serviço de streaming ou o próprio coletor do seu SIEM/observabilidade).
Nesse barramento, você aplica três etapas fundamentais:
– Normalização: transformar formatos diferentes em um modelo comum
– Enriquecimento: adicionar contexto (CMDB, tags, dados de identidade)
– Roteamento: decidir o que vai para SIEM, o que vai para observabilidade, o que vai para arquivo frio
Esse design já evita metade das dores de cabeça futuras, porque desde cedo você separa “logs que ajudam a achar bugs” de “logs que ajudam a achar ataques”, sem perder o contexto compartilhado.
Erro #4: Não pensar em custo de ingestão e retenção
A maioria dos iniciantes só descobre o custo de log quando chega a primeira fatura séria. SIEM normalmente cobra por volume de ingestão e/ou armazenamento. Ferramentas de observabilidade também podem cobrar por volume de logs ou eventos por segundo. Se você mandar tudo em alta retenção para todo lugar, é questão de tempo até alguém pedir para desligar metade do monitoramento.
A saída é tratar logs como um recurso com níveis de serviço. Pergunte para cada tipo de log:
– Ele é essencial para resposta a incidentes de segurança?
– Ele é essencial para debugar problemas de produção?
– Com que frequência realmente é consultado?
– Em quanto tempo você precisa acessá-lo (online vs arquivado)?
Com isso, crie políticas de retenção diferenciadas. Por exemplo: logs críticos de segurança mantidos 1 ano no SIEM, logs de aplicação detalhados 30 dias quentes + 11 meses em armazenamento frio. E comunique isso claramente para as áreas que vão consumir esses dados.
Erro #5: Alertas demais, automação de menos

Outro caminho certo para o fracasso é criar centenas de regras de alerta logo no início, copiando “best practices” genéricas sem adaptar ao seu ambiente. Em multi cloud, isso multiplica o ruído porque o mesmo tipo de evento aparece de formas ligeiramente diferentes em cada provedor, gerando duplicações e falsos positivos intermináveis.
Comece pequeno e certeiro. Priorize:
– Acessos anômalos a contas privilegiadas
– Mudanças críticas de configuração em recursos sensíveis
– Falhas de autenticação em massa
– Atividades fora de região esperada ou fora de horário de trabalho
E sempre que criar uma regra de detecção, já pense no que pode ser automatizado na resposta: adicionar tags de “suspeito”, isolar recurso, abrir ticket, notificar time certo. Quanto mais previsível a ação, mais faz sentido automatizar.
Conectando times: segurança, DevOps e SRE na mesma página
Não adianta ter a melhor arquitetura se cada time só olha para o seu pedaço e ninguém concorda sobre o que é “evento importante”. Integrar SIEM e observabilidade com logs de múltiplos provedores cloud é tanto sobre tecnologia quanto sobre alinhamento entre equipes.
Uma prática que funciona bem é ter playbooks conjuntos de incidentes mistos: por exemplo, um cenário em que uma queda de performance pode ser sintoma de ataque ou falha de dependência. Nessas situações:
– SRE traz o contexto de métricas e traces
– Segurança traz o contexto de atividade suspeita e histórico de ameaças
– DevOps ajuda a entender o código e o pipeline que podem estar envolvidos
Essa colaboração só rola se os dados estiverem acessíveis em um lugar onde todos consigam consultar, com linguagem de busca razoavelmente uniforme.
Erro #6: Desprezar contexto de negócio nos logs
Muita gente foca em campos técnicos (IP, porta, usuário) e esquece de adicionar contexto de negócio nos logs: qual sistema, qual cliente, qual produto, qual criticidade. Em multi cloud, isso é ainda mais crucial, porque o mesmo tipo de evento pode ter impacto completamente diferente dependendo do serviço envolvido.
Inclua, sempre que possível:
– Tags de ambiente (prod, staging, dev)
– Serviço ou domínio de negócio (pagamentos, cadastro, relatórios)
– Dono do sistema (squad, equipe)
– Nível de criticidade (alto, médio, baixo)
Isso transforma a investigação no SIEM e na observabilidade em algo alinhado com o risco real, e facilita priorizar incidentes que impactam receita ou compliance.
Escolhendo ferramentas sem cair em armadilhas de marketing
Quando se fala em ferramentas SIEM para múltiplas clouds, todo mundo promete integração automática, detecção por IA, dashboards mágicos e por aí vai. A mesma coisa acontece com o software de segurança e observabilidade para nuvem híbrida e multi cloud: dezenas de logos bonitos, mas pouca clareza sobre como aquilo se encaixa no seu fluxo real de logs.
Na hora de escolher, foque em perguntas práticas:
– Quão fácil é integrar com os serviços nativos de log de cada cloud?
– Dá para aplicar seu próprio modelo de dados e normalização?
– Como funciona o custo de ingestão, retenção e consulta?
– Consigo separar claramente o que é caso de uso de segurança e o que é observabilidade?
– A ferramenta suporta automação e integração com seus playbooks existentes?
Faça POCs com casos de uso reais, não só com “hello world” de log. Simule um incidente atravessando duas clouds e veja quanto tempo leva para chegar à causa raiz.
Boas práticas para uma integração saudável
Para amarrar tudo, algumas recomendações pragmáticas para quem quer começar direito ou consertar o que já foi feito às pressas:
– Defina desde cedo um modelo de dados comum para logs
– Crie um pipeline central de ingestão usado por todas as clouds
– Separe casos de uso de segurança e de observabilidade, mas compartilhe o mesmo contexto
– Trate custo de log como parte do desenho de arquitetura, não como detalhe financeiro
– Comece com poucas regras de alerta, bem pensadas, e refine com base na experiência real
– Documente e treine as equipes sobre como consultar e interpretar os logs
Lembre-se: ferramenta nenhuma, sozinha, vai “mágicamente” integrar seu SIEM com observabilidade. O que faz a diferença é consistência nas decisões, clareza sobre o que você quer enxergar e disciplina para evitar o acúmulo de “gambiarras” de logging em cada novo projeto.
Resumo para quem está começando agora

Se você está dando os primeiros passos, evite os grandes erros: não ligue todos os logs no máximo, não deixe cada time inventar seu formato, e não trate cada cloud como um mundo separado. Comece pequeno, foque nas fontes de logs mais importantes, padronize o básico, centralize o pipeline e use o SIEM e a observabilidade como duas lentes diferentes para olhar a mesma realidade.
Com isso, sua integração deixa de ser um Frankenstein de conectores e passa a ser uma base sólida para crescer, sem se perder em meio à enxurrada de eventos que um ambiente multi cloud inevitavelmente vai gerar.