Over the last 12 months cloud security has turned into a moving target. Attackers are faster, they know cloud platforms almost as well as your SRE team, and they’re very good at chaining “small” mistakes into full‑blown incidents. Below is a practical walkthrough of what actually changed, why it matters, and what you can do this week rather than “someday”.
—
What really changed in cloud attacks this year
When people talk about ataques em cloud computing últimas tendências, they often throw everything in one bucket. Let’s unpack the basics so the rest of the article is easier to apply.
Cloud infrastructure in this context means all the building blocks your apps run on: virtual machines, containers, serverless functions, networks, storage, managed databases, identities (users/roles), keys, CI/CD pipelines and the management plane (AWS Console, Azure Portal, etc.).
The big shift this year is that attackers are behaving much more like cloud engineers:
– They understand IAM policies, security groups, VPCs, Kubernetes RBAC and managed services.
– They use automation to scan for misconfigurations and leaked credentials.
– They move laterally *inside* the cloud instead of just dropping ransomware and running.
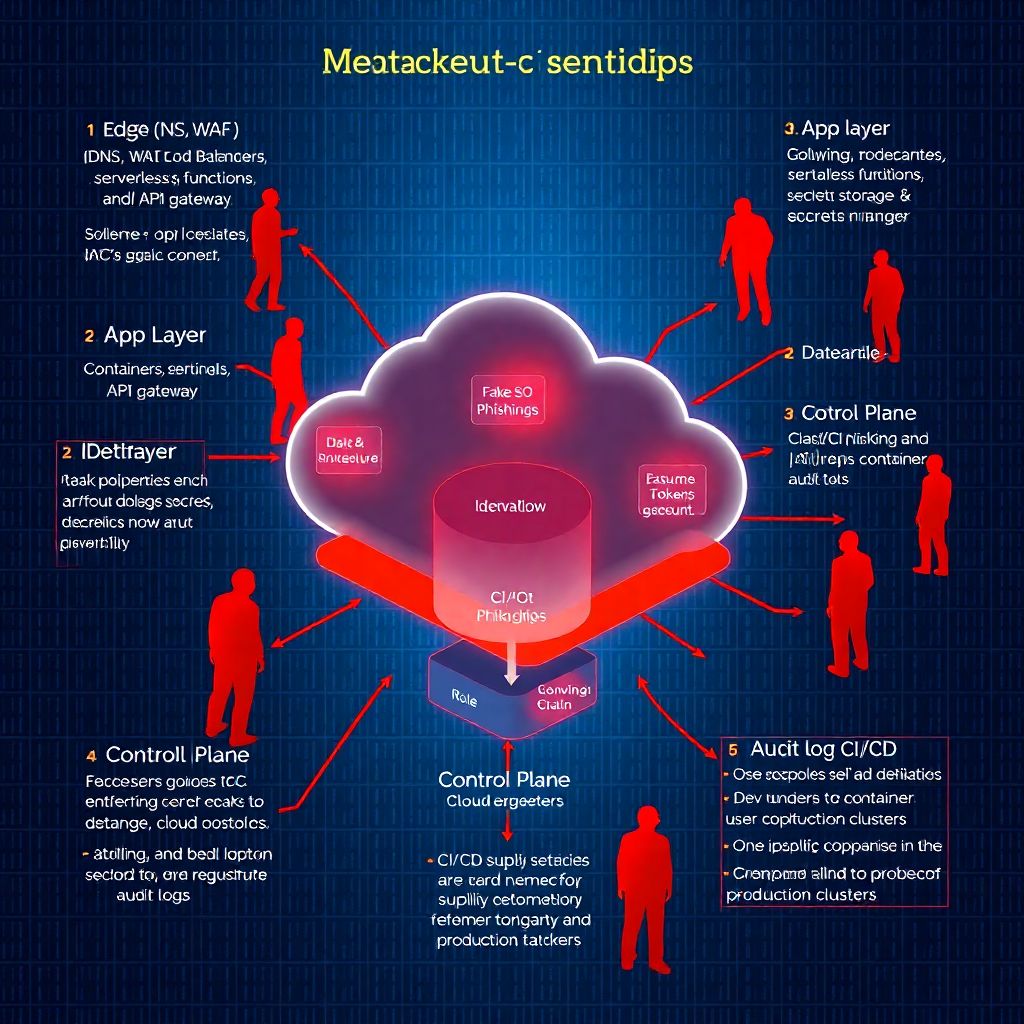
A simple mental diagram of a typical environment today looks like this:
– Edge: DNS → WAF → Load Balancer
– App layer: Containers / Functions → API Gateway
– Data & identity: Databases, object storage, IAM roles, secrets manager
– Control plane: CI/CD, IaC repositories, cloud console, audit logs
Most of the new attack patterns you’ll see are about jumping from the edge into data and identity through weak links in this chain.
—
Trend 1: Identity and access abuse beats “classic” server hacking
Why identities became the main entry point
Instead of pounding on open ports, attackers now hunt for tokens, keys and roles. Cloud identities – users, groups, roles, service accounts – effectively *are* your perimeter. If an attacker gets a privileged role, they don’t need an exploit; they just call the normal cloud APIs.
Common identity‑centric moves in the last 12 months:
– Stealing web session cookies to bypass MFA.
– Abusing “assume role” flows in multi‑account setups.
– Escalating from a low‑privilege role to admin via overly broad policies.
– Using stolen CI/CD service tokens to deploy malicious code or backdoors.
A simple flow diagram in text:
1. Phishing email → user logs into fake SSO page
2. Attacker captures SSO token
3. Token used to access cloud console with user’s role
4. Role allows “assumeRole” into a more privileged account
5. Attacker creates new backdoor user or access key and persists
This is why treating SSO and IAM as “just IT stuff” is dangerous. They *are* part of your security boundary.
Practical defenses you can implement quickly
When you ask yourself como proteger infraestrutura em nuvem contra hackers, start with identity; it’s the highest ROI.
Priority actions:
– Lock down administrative paths
– Put all admin access behind conditional policies (allowed only from VPN or corporate IPs).
– Require phishing‑resistant MFA (FIDO2 tokens, platform authenticators) for admins.
– Reduce blast radius with strong least privilege
– Replace wildcard permissions (`*`) in IAM roles with narrow, resource‑scoped grants.
– Use short‑lived credentials (STS, workload identity federation) instead of long‑lived keys.
– Harden tokens and sessions
– Enforce short session lifetimes and strict re‑auth for sensitive actions.
– Monitor for unusual token use: new geo, new device, out‑of‑hours access.
These measures directly cut the probability that a single stolen token leads to a full environment takeover.
—
Trend 2: Supply chain and CI/CD pipelines as attack highways
From code to production: where attackers sneak in
The second big trend: instead of breaching production directly, attackers compromise the path *into* production – your CI/CD tooling, build agents, registries and IaC repositories.
Typical modern pipeline (simplified “diagram”):
– Dev laptops → Git hosting → CI system
– CI runners → Build artifacts → Container registry
– Deployment tool → Kubernetes / Functions / VMs in cloud
Weakness at any step can give an attacker a way to run code in your environment with legitimate automation credentials.
Recent patterns include:
– Malicious dependencies uploaded to public registries and silently pulled into your builds.
– Compromise of self‑hosted runners that hold powerful cloud tokens.
– Poisoned base container images used across dozens of microservices.
– Manipulation of IaC templates to open extra ports or grant excess permissions.
Making your pipelines harder to abuse
To make this actionable, treat your pipeline like production:
– Lock down CI/CD identities
– Give each pipeline a dedicated, minimal‑privilege role.
– Rotate CI/CD tokens frequently and ensure they are short‑lived.
– Make artifacts and configs verifiable
– Sign artifacts (containers, binaries) and enforce signature checks on deploy.
– Require code review for IaC changes that touch security‑sensitive resources (network, IAM, secrets).
– Isolate critical runners
– Run privileged or production‑deploy runners in dedicated, hardened environments, not shared with dev/test.
– Ensure runners have no direct inbound internet access; they initiate connections out only.
This shift doesn’t require fancy tools; it requires treating dev tooling as “Tier 0” infrastructure instead of a convenience service.
—
Trend 3: Data theft and cloud‑native ransomware
From simple storage leaks to multi‑stage extortion
Data remains the prize. Over the last year, attackers increasingly:
– Combine misconfigured storage (S3 buckets, blobs) with credential theft.
– Exfiltrate backups from cloud backup services instead of attacking live databases.
– Leverage cloud‑native snapshots (EBS, disks, volumes) to copy entire datasets.
Cloud‑native ransomware is also evolving: instead of encrypting files on VMs, actors abuse your own permissions to:
– Rotate database keys or delete KMS keys.
– Encrypt objects in place with new keys they control.
– Destroy backups and snapshots, then demand payment to “restore” configurations or keys.
This changes how you must think about segurança em nuvem proteção contra ataques cibernéticos: it’s no longer just about agents on VMs but also about hardening how your cloud services can modify or delete each other’s data.
Defenses that directly impact data‑centric attacks
Concretely:
– Treat backups as a separate trust domain
– Store backups in logically separate accounts or subscriptions with different keys.
– Use immutable or write‑once storage features where available (object lock, vault lock).
– Minimize data access scopes
– Segment data by sensitivity, not only by app. Highly sensitive data should live in separate projects/accounts.
– Give apps narrowly scoped roles that can read/write only specific datasets, not all storage or all databases.
– Automate anomaly detection for data flows
– Alert on unusual spikes in snapshot creation, export jobs, or large object downloads from atypical regions.
– Cross‑check these spikes with IAM activity: new roles, newly granted privileges, or suspicious key usage.
This combination makes it significantly harder for an attacker to quietly siphon or destroy your core data.
—
Trend 4: Misconfigurations and IaC drift are prime targets
Why “just one misconfigured rule” hurts more now
Misconfigurations are not new, but two things changed:
1. Cloud environments are more complex (multi‑cloud, multi‑account, hybrid).
2. Attackers now use automated tools to constantly scan for small mistakes.
Typical exploitable issues:
– Publicly exposed storage buckets with list or write permissions.
– Security groups allowing `0.0.0.0/0` on admin ports or internal services.
– Overly permissive cross‑account roles that anyone can assume.
– Forgotten test environments with real credentials and real data.
Cloud‑specific challenge: even if your infrastructure as code is fine, people can still change settings manually in consoles, creating drift between what’s declared and what actually runs.
Practical way to keep configs under control
You don’t need perfection, you need fast detection and correction:
– Make IaC the source of truth
– Enforce that all cloud resources must come from Terraform, CloudFormation, ARM/Bicep, etc.
– Block manual console changes for key services where possible, or at least alert on them.
– Continuously scan for misconfigs
– Run daily or even hourly configuration scans against your accounts.
– Integrate findings into the same backlog as application bugs with SLAs by severity.
– Segment environments
– Strictly separate dev, staging and prod into different accounts or subscriptions.
– Use explicit, audited bridges (e.g., specific peering, specific roles) to limit unintended lateral movement.
Compared to classic on‑prem environments, cloud gives you much richer APIs and metadata, which means you can automate checks instead of relying on manual audits. Use that to your advantage.
—
Detection and response: monitoring that keeps up with attackers
Why monitoring has to move beyond “CPU and 500 errors”
Traditional logs and metrics (CPU, memory, HTTP 5xx) barely scratch the surface when attackers use valid identities and APIs. What you really need is context: *who* did *what* in *which* account, from *where*, and *how often*.
This is where serviços de monitoramento e detecção de ameaças em cloud come into play. Modern cloud‑aware monitoring stacks combine:
– Cloud provider audit logs (API calls, console logins, role assumptions).
– Network flow logs (VPC flow, firewall logs, WAF events).
– Application and API logs enriched with user IDs and tenant IDs.
– Identity events from SSO, IdP and device posture checks.
Think of the following conceptual diagram:
– Data sources → logs / events from cloud, apps, identity
– Processing → normalization, correlation, anomaly detection
– Output → alerts, playbooks, dashboards with attack timelines
To make this concrete in your environment:
– Unify logging across accounts and regions
– Stream all audit logs into a central, write‑only logging account or project.
– Ensure logs are immutable and retained long enough for investigations.
– Define a handful of high‑signal detections
– New IAM user or role with admin privileges created outside change windows.
– Public exposure of previously private buckets or databases.
– Token or role being used from a country or ASN you never operate in.
– Automate basic responses
– Auto‑revoke newly created risky keys until reviewed.
– Auto‑quarantine suspicious workloads by applying restrictive security groups or policies.
– Auto‑page the on‑call team with enough context to act (who, what, where, when).
You don’t need a massive SOC from day one; start with three to five high‑impact detections and iteratively expand.
—
Choosing and combining cloud security solutions
What actually helps in practice

Given this threat landscape, melhores soluções de segurança para infraestrutura cloud are rarely a single product. Instead, they’re a stack of focused capabilities that work together.
A practical, vendor‑agnostic checklist of what you likely need:
– Cloud‑native guardrails
– Identity and access analyzers, permission boundaries and policy linters.
– Managed WAF and DDoS protection at the edge.
– Posture management
– Continuous scanning of configurations against best practices and compliance baselines.
– Drift detection between IaC definitions and the live environment.
– Workload and data protection
– Runtime security for containers and serverless (syscall, network behavior, process anomalies).
– Built‑in or external tools for key management, encryption and data access monitoring.
– Central visibility and response
– Log aggregation and a security‑aware analytics layer (SIEM/XDR).
– Incident response playbooks integrated with ticketing and chat tools.
When you evaluate products, map them back to the concrete threats discussed above: identity abuse, supply chain, data exfiltration, misconfigurations. If something can’t show you clearly *which* of those risks it reduces and *how*, treat the promises with caution.
—
Turning trends into a 90‑day action plan
To wrap this up in a practical way, here’s how you can use the last 12 months of attack trends to shape the next 90 days of work.
Next 30 days
– Inventory your cloud accounts, projects and subscriptions; identify admins and high‑privilege roles.
– Enable and centralize audit logging everywhere; fix any gaps in regions or services.
– Remove obviously over‑permissive roles and security groups (`*:*`, `0.0.0.0/0` on admin ports).
Days 31–60
– Move critical resources (data stores, backups) into segmented accounts with tighter IAM.
– Harden CI/CD: separate runners, rotate and reduce pipeline permissions, add mandatory review on IaC.
– Implement 3–5 high‑signal detections focused on identity and data anomalies.
Days 61–90
– Roll out phishing‑resistant MFA for all admins and sensitive roles.
– Enforce “IaC only” for new resources and start tackling drift for existing ones.
– Run a red‑team‑style exercise or tabletop scenario focused on a cloud identity breach and see how far an attacker could get.
Cloud attacks are evolving fast, but your advantage is that everything is programmable. Use that programmability not just to ship features, but also to automate guardrails, checks and responses. If you focus on identity, supply chain, data protection and misconfiguration control, you’ll be well aligned with the real threats that have dominated cloud incidents over the past year.