Why cloud data protection is trickier than it looks
Moving data to the cloud sounds simple: upload, connect your app, and enjoy the scalability. The catch appears when that spreadsheet with customer IDs, card numbers or health info ends up stored right next to logs, images and test data, tudo misturado. Sensitive information loses its physical boundaries, and suddenly anyone with the wrong permission, a leaked access token or a misconfigured bucket can see much more than they should. If you want real segurança de dados na nuvem criptografia tokenização kms funcionando de verdade, you need to treat data protection as part of your application design, not a last-minute security checkbox.
Step zero: map what is really “sensitive” in your cloud
Before touching keys, ciphers or fancy APIs, you need brutal clarity about what exactly you are protecting. In most companies, “sensitive data” is spread across databases, object storage, logs, analytics tools and even CI/CD pipelines. A pragmatic approach is to start with two questions: what data would generate legal trouble or customer damage if leaked, and where does this data actually live in your cloud? Focus first on a few concrete fields: CPF or national IDs, payment details, passwords (hashes), health data, internal financial numbers. Then track how each of these travels between services, queues, backups and data lakes; this map will guide which encryption model and tokenization flow make sense for you.
Practical checklist to identify sensitive data
To avoid turning this into an endless compliance exercise, keep it short and focused. Go service by service and note only what matters: which fields are truly confidential, who uses them and why, and whether they must be readable by humans or only processed by machines. In practice, a quick workshop with engineering, security and product is far more effective than sending out questionnaires. Write down concrete decisions, like “card PAN never stored, only token from provider”, “logs must not contain emails”, “analytics can only keep hashed identifiers”. This becomes your living contract and will later feed directly into key policies, IAM roles and which API endpoints are allowed to see the cleartext data at all.
How to use encryption in the cloud without sabotaging performance
Most cloud providers offer encryption at rest by default, and that is great, but not enough. If an attacker gets valid credentials to your database or storage, they see everything decrypted transparently. The real game is how you use application-level encryption: deciding which fields are encrypted before being written, how keys are rotated and which services are allowed to decrypt. When people ask como proteger dados sensíveis na nuvem com criptografia, the honest answer is: stop thinking only in terms of turning on a checkbox, and start thinking about where in the data flow encryption happens and who holds the keys. That is the difference between “the provider protects the disk” and “you control who can see each individual field.”
Field-level encryption that developers actually can maintain
Imagine a customer table where only three fields are really critical: ID document, full card number and maybe some health flag. A straightforward model is to encrypt just these fields at the application layer before sending them to the database. You call a library that talks to your KMS, gets a data key, encrypts the value and stores the ciphertext plus metadata about which key was used. Decryption is only allowed in a small set of backend services, never in frontend or logging layers. Performance impact is usually modest if you keep the operation at field level rather than encrypting whole rows, and indexing can still be done on non-sensitive columns. The main trap is developers bypassing the library; solve this with clear SDKs and code reviews, not with wishful thinking.
Transport encryption: don’t break the chain
It’s easy to obsess over database encryption and forget the pipes. If any hop between services is still using HTTP plain text or weak ciphers, an internal attacker or compromised pod can sniff traffic. Make TLS compulsory everywhere: between microservices, from workloads to managed databases, from applications to external APIs. Use modern protocols and disable legacy versions that are still enabled “for compatibility”. Certificates should be rotated automatically, ideally integrated with your KMS or secrets manager. Think of it as plumbing: one leaky pipe ruins the clean water in the whole system, no matter how fancy your storage is.
Tokenization: keeping format but hiding meaning
Encryption is great, but sometimes systems need something that looks like the real data without exposing it. That’s where tokenization shines. Instead of storing a credit card number, you store a token that has the same size and maybe even passes simple validation rules, but is meaningless outside your tokenization service. For analytics, sandbox environments or third-party integrations, this allows you to keep functional workflows without leaving sensitive information exposed. Well-designed soluções de tokenização de dados na nuvem para empresas tend to centralize the logic in a dedicated service, making it easier to audit and monitor access than spreading dozens of custom “masking” utilities across the codebase.
Designing a practical tokenization flow
A good starting point is to treat tokenization as its own microservice with a very narrow mission: receive clear data, return a token; receive a valid token, return the clear data only if strict policies allow it. Access to detokenization must be severely limited, often to just a few backend services in the production environment. Sandbox, BI tools and support dashboards should only see tokens or partially masked values. Store the mapping between token and clear data in a dedicated encrypted database, using separate keys from the rest of your platform. Add strict rate limiting and logging: any unusual detokenization pattern should instantly raise an alert, because it means someone is trying to pull data in bulk, even with valid credentials.
When tokenization beats anonymization
A common misunderstanding is confusing tokenization with anonymization. Anonymized data should not be reversible, while tokens are designed to be reversed under controlled conditions. Use tokenization when you still need to run operations tied to an individual, like chargebacks or customer support, but want to hide the original values from most systems. Use true anonymization when legal or compliance rules demand that nobody, not even administrators, can reconstruct the original record. In practice, many teams start with tokenization as a safer stepping stone, especially for payments, then later add separate anonymized datasets for research or data science, built from already-tokenized sources.
KMS: your keys, your rules (if you set them correctly)
Key Management Services are the backbone of any serious encryption strategy in the cloud. They store master keys, generate data keys and enforce who can use which key for what action. The nuance is that misconfigured policies can turn KMS into just another shared secret bucket. Effective gerenciamento de chaves kms na nuvem para dados confidenciais starts by defining ownership: who is responsible for each key, what data it protects, and how long it should live. Then you translate these decisions into IAM policies and key usage constraints, ensuring that only specific services in specific accounts and regions can call decrypt. Anything broader will eventually be abused, accidentally or intentionally.
Key separation and rotation that won’t kill your uptime
A practical rule of thumb is to avoid a single master key for everything. Split keys by data sensitivity and environment: one set for production customer identities, another for internal metrics, another for logs, and never reuse production keys in dev or staging. Rotation should be planned like a small migration: test the process on non-critical datasets, ensure that your applications always know which key encrypted which piece of data, and allow for a period where both old and new keys can decrypt. Automate as much as possible: scheduled rotations, alias updates and alarms when a key is used in unexpected patterns. This keeps your melhores práticas de criptografia e kms em cloud computing from staying only on slides and makes them visible in everyday operations.
Least privilege for KMS in real setups
On paper, “least privilege” sounds obvious; in reality, it often collapses into overly broad roles created under time pressure. Reverse this tendency by starting from data, not from services. Ask which service truly needs to see cleartext for a given field and assign KMS permissions only to that service’s role, blocking everyone else, including admin dashboards. For batch jobs or ad-hoc reports, prefer derived datasets that are already masked or tokenized, instead of giving temporary wide KMS access. Regularly review which identities can call decrypt on high-value keys, and cut down anything that looks “temporary” but has been there for months. Logs from KMS are gold: they tell you exactly who decrypted what, and can expose misuses long before a leak becomes public.
Bringing it together: a realistic reference flow
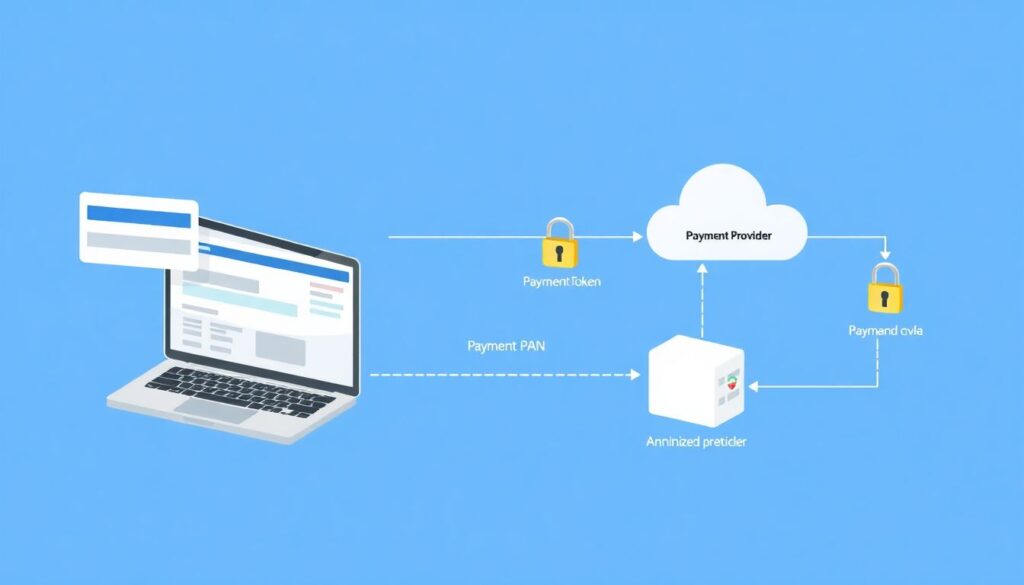
To make all this less abstract, imagine a typical SaaS storing customer data and payment details in the cloud. The web app sends card details to a backend, which never stores the raw PAN. Instead, it calls a payment provider and receives a payment token, while simultaneously sending some metadata to your internal tokenization service for internal references. Customer IDs and emails are stored in the main database with field-level encryption using keys managed by KMS, and only a narrow set of microservices can decrypt. Logs are configured to drop or mask any sensitive field before leaving the app, and backups are encrypted with distinct keys whose usage is tightly controlled. When a support agent opens a customer profile, the UI calls a backend that fetches data, partially masks it, and never exposes the full cleartext unnecessarily.
What to monitor so the controls don’t rot over time
Even the best designed architecture will drift if you don’t watch it. Set alerts for new resources storing data without encryption, unusually permissive IAM policies touching KMS keys and spikes in detokenization or decrypt operations. Include security checks in CI/CD: if a developer adds a new database table for customer data, the pipeline should fail unless encryption and masking rules are defined. Periodic drills help too: simulate an incident where a specific key might be compromised and exercise the rotation, revocation and re-encryption procedures. Over time, your teams start to treat encryption, tokenization and key management not as exotic features, but as the normal way to deploy anything that even smells like confidential data.
Start small, but start with real data
Trying to redesign everything at once usually leads to big diagrams and zero implementation. Pick one critical flow—often payments, identity or health information—and apply the full stack there: field-level encryption, strict KMS policies, tokenization for downstream systems and aggressive logging and monitoring. Once you see that this doesn’t break your performance or developer velocity, replicate the pattern to other areas. Instead of relying only on your cloud provider defaults, treat encryption and tokenization as first-class application features. Done this way, your cloud setup stops being a mysterious black box and becomes a controlled environment where sensitive data is predictable, traceable and guarded at every step of its journey.