Por que grandes incidentes em cloud mudaram de figura
Nos primeiros anos da computação em nuvem, a maior dúvida das empresas era quase filosófica: “posso confiar meus dados a alguém que não vejo e não controlo fisicamente?”. Hoje o cenário é outro. A nuvem venceu essa discussão, mas as manchetes de notícias sobre vazamento de dados em cloud computing mostraram que o problema nunca foi apenas “a nuvem”, e sim como ela é configurada, monitorada e compartilhada entre times. Em vez de perguntarmos se cloud é segura, a pergunta madura passou a ser: “como reduzir o impacto quando algo inevitavelmente der errado?”. É aqui que notícias, autópsias técnicas e análises públicas de incidentes de segurança em provedores de cloud se tornaram quase tão valiosas quanto as próprias ferramentas de proteção, porque revelam padrões de erro, pontos cegos e, principalmente, decisões organizacionais que abriram a porta para o ataque.
Em resumo: olhar para grandes falhas virou parte do kit de sobrevivência, não um passatempo mórbido de quem gosta de cyber drama.
Case 1: Capital One e AWS – quando um pequeno detalhe vira desastre
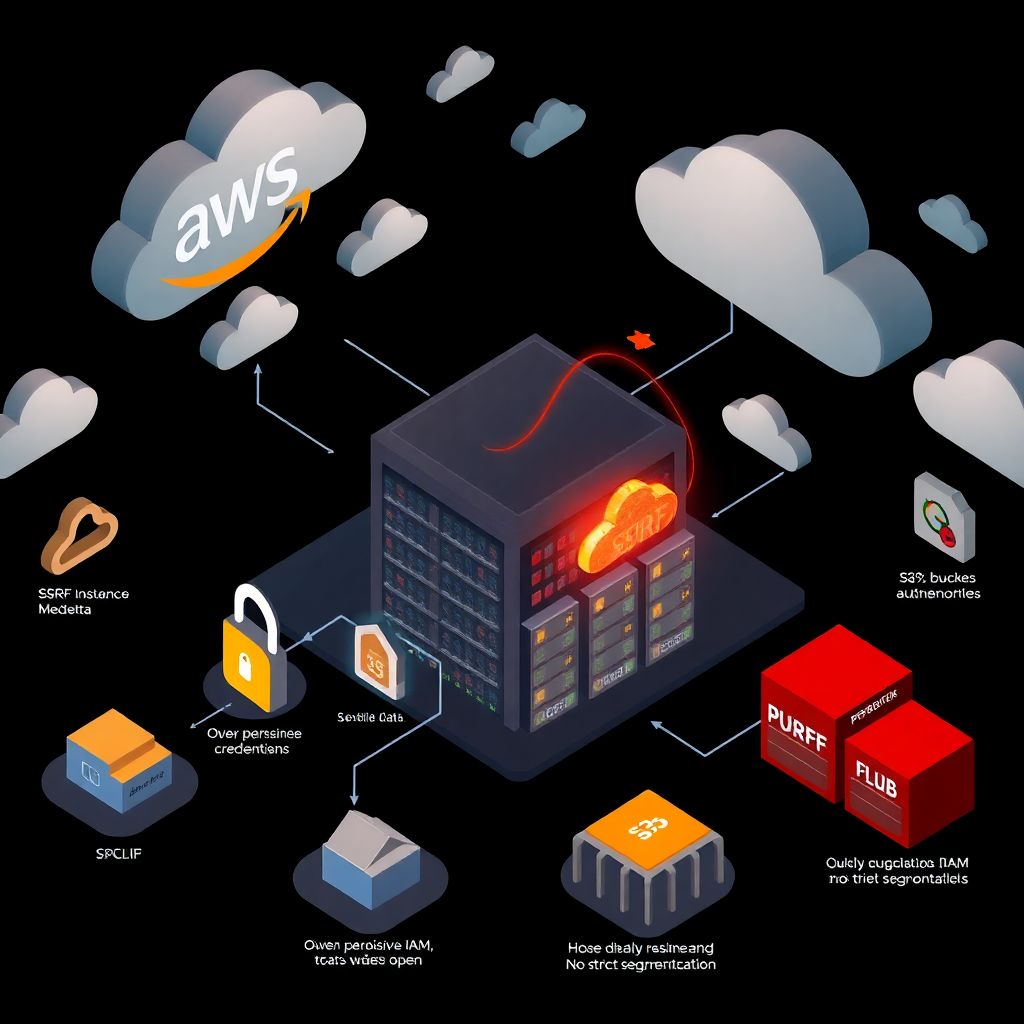
Um dos casos mais estudados em análise de grandes ataques cibernéticos em nuvem é o incidente da Capital One, em 2019, rodando em AWS. Não foi um “hack mágico” contra o provedor; foi uma combinação perigosa de falha de configuração com brecha em um serviço da própria AWS. A invasora explorou uma vulnerabilidade de Server-Side Request Forgery (SSRF) em uma aplicação web, conseguiu roubar credenciais temporárias da instância e, a partir daí, acessou buckets S3 com dados sensíveis de mais de 100 milhões de clientes. A nuvem funcionou exatamente como projetado: quem tinha credencial válida, tinha acesso. O erro estava em: regras de firewall excessivamente permissivas, política IAM ampla demais (“pode listar e ler muitos buckets”) e ausência de segmentação rígida de dados. O resultado virou exemplo clássico de incidentes de segurança em provedores de cloud em que o fator humano e o design de permissões pesaram mais que qualquer tecnologia.
Lição nada sutil: “funcionar” não é sinônimo de “estar seguro”.
O que aprender com Capital One na prática
Em vez de apenas repetir “use o princípio de privilégio mínimo”, vale traduzir isso em ações diárias replicáveis em qualquer ambiente, seja em AWS, Azure ou Google Cloud. Ao examinar o caso, equipes maduras começaram a rever três frentes: como concedem permissões a máquinas e serviços, como definem o que é “ambiente sensível” e o que é “experimento”, e como automatizam a detecção de acessos estranhos em dados críticos. Muitas empresas perceberam que confiavam demais na fronteira da aplicação web e pouco nos mecanismos nativos da nuvem. Outro aprendizado foi cultural: segurança não pode ser um checklist tardio, anexado ao final de um projeto. Nos relatórios públicos do caso, fica claro que o ataque aproveitou componentes que ninguém mais revisava, porque “já estavam em produção há tempos”, o que é quase um convite aberto para exploração silenciosa.
Boas práticas que se consolidaram depois desse caso:
– IAM com escopo mínimo, por recurso e por tarefa, não “por conveniência”
– Separação rígida entre buckets de produção e de teste, com contas diferentes
– Monitoramento contínuo de acessos a dados sensíveis com alertas acionáveis
– Revisões periódicas de regras de firewall e de uso de metadados de instância
Case 2: buckets públicos e o lado B da conveniência
Milhares de incidentes nunca chegam às manchetes, mas formam um padrão claro: dados expostos em storage público, por descuido, pressa ou desconhecimento. Casos de empresas que deixaram buckets S3, Google Cloud Storage ou Azure Blob públicos – com bases de clientes, logs de aplicações, arquivos de backup – são tão frequentes que viraram quase um gênero próprio dentro das notícias sobre vazamento de dados em cloud computing. Muitas dessas ocorrências não envolvem sequer invasão com exploração avançada; basta um scanner automatizado que varre a internet procurando armazenamento acessível sem autenticação, algo que hoje qualquer atacante de nível médio consegue operar. O que mudou nos últimos anos foi a reação dos provedores: AWS, Azure e Google passaram a bloquear, por padrão, certas configurações públicas e a exibir alertas mais agressivos no painel, mas, mesmo assim, configurações legadas e exceções “temporárias” permanecem como fontes de risco.
Na maioria das vezes, o vazamento foi criado em segundos, para “resolver um problema rápido de acesso do time”.
Como matar o problema dos storages expostos
A boa notícia é que essa categoria de falhas de segurança em nuvem aws azure google cloud é uma das mais fáceis de cortar pela raiz. Na prática, a solução não é confiar que todos os times vão configurar tudo certo o tempo todo, mas sim construir trilhos seguros (guardrails) que impedem acidentalmente o estado perigoso. Empresas que aprenderam com esses episódios criaram camadas de proteção: políticas organizacionais que proíbem buckets públicos, automação que revoga permissões arriscadas e scanners periódicos que tratam storage público como vulnerabilidade crítica. Em vez de discutir caso a caso, define-se um “padrão inegociável”: dados de clientes nunca ficam em recurso publicamente acessível, ponto final. Para isso ser gerenciável, é preciso integrar segurança à esteira de desenvolvimento, de modo que o próprio pipeline de deploy interrompa mudanças que violem essas regras, reduzindo o espaço para o erro humano sob pressão.
Checklist mínimo para fechar essa porta:
– Política organizacional bloqueando storage público por padrão
– Ferramentas de descoberta contínua de buckets/blobs públicos
– Tags obrigatórias para classificar sensibilidade de dados
– Revisão automatizada de infraestrutura como código antes do deploy
Case 3: ChaosDB e o “superpoder” acidental no Azure Cosmos DB
Nem todos os incidentes partem de erro do cliente; alguns nascem no próprio design do provedor. Em 2021, pesquisadores descobriram a falha apelidada de ChaosDB no Azure Cosmos DB. Explorando integrações com o Jupyter Notebook, era possível obter chaves de acesso de outras instâncias de clientes, potencialmente lendo ou alterando dados de bancos que nada tinham a ver entre si. Embora não haja indícios públicos de exploração em larga escala, o simples fato de uma vulnerabilidade de isolamento desse tipo existir preocupa bastante. É um lembrete de que, mesmo com boas práticas para segurança em provedores de cloud do lado do cliente, ainda existe o chamado risco de “plataforma compartilhada”. A resposta da Microsoft foi rápida: desligou o recurso vulnerável, notificou clientes afetados, rotacionou chaves e reforçou a segmentação interna. Ainda assim, o caso ficou como marco na percepção de que depender 100% do provedor, sem nenhuma camada extra de proteção própria, é uma aposta arriscada para sistemas críticos.
Esse tipo de falha é raro, mas quando acontece, o impacto potencial é muito maior que o de um bucket mal configurado.
O que ChaosDB ensinou sobre dependência do provedor

Da análise desse tipo de incidente surgiram algumas lições que extrapolam a conversa sobre um provedor específico. Primeiro: cripto forte do lado do cliente volta à mesa como defesa estrutural. Se dados estão cifrados com chaves geridas pela própria empresa (client-side encryption), o vazamento de chaves de acesso do banco não entrega o conteúdo em texto puro. Segundo: gestão agressiva de rotação de segredos. Muitos clientes só rotacionavam chaves quando havia troca de time ou de fornecedor; depois de ChaosDB, ficou claro que isso precisa ser rotina automática, justamente para reduzir a janela de impacto de qualquer falha sistêmica. Terceiro: visibilidade de dependências. Muitas companhias usavam Cosmos DB sem ter clareza interna de quais aplicações dependiam dele, algo que dificulta reagir rápido quando chega um alerta de incidente.
Três práticas acionáveis aqui:
– Adotar criptografia end-to-end para dados sensíveis, com chaves próprias
– Automatizar rotação de segredos (chaves, tokens, senhas) em ciclos curtos
– Manter inventário vivo de serviços cloud críticos e de quem os usa
Case 4: falhas de identidade e fuga lateral em ambiente multi-cloud
Com a popularização de arquiteturas multi-cloud, incidentes passaram a explorar o elo mais fraco entre identidades, e não apenas brechas em um único provedor. Um cenário cada vez mais comum: uma credencial comprometida em um cluster Kubernetes em Google Cloud é usada para acessar um sistema de logging central, que, por sua vez, contém chaves reutilizadas em Azure; a partir daí, o atacante consegue pivoteamento lateral entre plataformas teoricamente independentes. Ainda que nem sempre isso vire manchete, relatórios internos e investigações independentes mostram esse padrão se repetindo. A raiz do problema está menos no Kubernetes ou no provedor em si, e mais na ausência de uma estratégia coerente de identidade e acesso: contas de serviço com privilégios amplos, tokens de longa duração, ausência de segregação por ambiente e inexistência de monitoramento centrado em comportamento de identidade.
Ou seja, o atacante não “invade clouds”; ele se comporta como um usuário privilegiado que ninguém está olhando.
Reforçando identidade como linha mestra de defesa
A partir dessas experiências, empresas mais maduras passaram a tratar identidade como plano de controle fundamental, não como detalhe de configuração em cada serviço. Isso implica consolidar autenticação forte, MFA obrigatório para humanos e rotação automática de credenciais para workloads. Em incidentes de segurança em provedores de cloud analisados nos últimos anos, uma constante é o uso de credenciais que jamais deveriam existir: chaves gravadas em repositórios Git, tokens de serviço com acesso amplo para “facilitar integrações”, contas de administrador compartilhadas por times inteiros. Corrigir isso é trabalho chato, mas extremamente efetivo. A estratégia vencedora combina: uso extensivo de perfis temporários, emissão de credenciais sob demanda via Identity Provider central, revisão periódica de permissões ativas e, principalmente, automação para revogar acessos desnecessários sem depender de pedidos manuais.
Pontos práticos para implementar agora:
– Proibir chaves estáticas de longa duração sempre que houver alternativa temporária
– Integrar todos os provedores a um IdP central, com políticas uniformes
– Monitorar logins e uso de credenciais como se fossem “transações financeiras”
– Automatizar detecção de chaves expostas em repositórios de código
O que realmente mudou na cobertura de incidentes em cloud
Se você comparar matérias de cinco ou dez anos atrás com a forma como hoje se reportam incidentes de segurança em provedores de cloud, uma diferença salta aos olhos: o foco se deslocou da “culpa” para a “causa raiz estruturante”. Em vez de apenas anunciar que “houve um ataque”, jornalistas especializados, pesquisadores e os próprios provedores passaram a detalhar vetores técnicos, decisões de arquitetura e falhas de processo. Isso melhorou a qualidade das discussões internas nas empresas, que agora podem usar essas análises como material para exercises de resposta a incidentes, simulações de tabletop e revisões de arquitetura. Além disso, os provedores vêm publicando notas de aprendizado pós-incidente bem mais completas, inclusive quando a falha não teve exploração pública confirmada. Essa transparência relativa cria um círculo virtuoso: mais detalhes levam a melhores defesas, que, por sua vez, elevam o nível de ataque necessário, o que também reduz a superfície de risco para organizações que aprendem com casos alheios.
Em outras palavras, cada grande incidente virou aula aberta, e ignorá-la é desperdiçar um curso gratuito.
Como usar notícias e análises para fortalecer sua própria segurança

Ler relatórios pós-incidente como quem consome fofoca tecnológica não acrescenta muito. O ganho real aparece quando a organização transforma cada caso em insumo concreto para mudanças de configuração, processos e treinamento. Uma forma eficiente de fazer isso é criar um pequeno rito interno: sempre que sair uma análise de grandes ataques cibernéticos em nuvem relevante ao seu setor, um grupo misto de segurança, desenvolvimento e operações se reúne por uma hora para discutir três pontos: isso poderia acontecer aqui? quais controles temos ou não para esse vetor? o que podemos ajustar nos próximos 30 dias? Assim, notícias deixam de ser ruído e viram backlog priorizado. Outra prática útil é manter um repositório interno de “casos de estudo em cloud”, com resumos curtos, mapeando cada incidente a controles específicos (por exemplo: “este caso se relaciona com criptografia, IAM, revisão de storage, monitoramento”).
Esse tipo de rotina cria uma cultura em que aprender com o erro dos outros é tão natural quanto fazer code review.
Checklist final: boas práticas modernas para segurança em provedores de cloud
Para amarrar os aprendizados desses casos, vale condensar o que hoje é visto como boas práticas para segurança em provedores de cloud, indo além das recomendações genéricas. A primeira camada é de higiene básica: infra como código versionada, revisada e testada; separação de contas por ambiente; nenhum dado sensível em storage público; MFA em tudo que envolva acesso administrativo. A segunda camada é de observabilidade: logs centralizados por provedor e por aplicação, alertas que olham para comportamento anômalo (não apenas falhas de login), e testes regulares de recuperação de incidentes. A terceira camada é de resiliência criptográfica e de identidade: criptografia de ponta a ponta para informações críticas, rotação contínua de segredos e uso pesado de identidades temporárias com privilégios mínimos. E, por cima de tudo, vem a camada cultural: tratar post-mortems públicos como insumo estratégico, investir em treino de incident response e garantir que dev, ops e segurança conversem usando a mesma linguagem.
Quando esses elementos se combinam, grandes incidentes deixam de ser apenas notícias assustadoras e se tornam mapas práticos de onde reforçar suas próprias defesas na nuvem.