Most teams want to move fast in the cloud, but nobody wants to be the headline about a leaked database or a hacked API. That’s where a modern pipeline DevSecOps na nuvem changes the story: вместо того, чтобы чинить уязвимости постфактум, вы строите процесс, в котором безопасность включена в каждое действие — от первого коммита до запросов в проде. Это не про тормоза, а про уверенность: вы нажимаете “deploy” и понимаете, что код прошёл чёткую, но автоматизированную проверку, а в рантайме за ним следит умная система, а не уставший человек с алертом в три ночи.
Why DevSecOps in the Cloud Changes the Game
From Manual Checks to Continuous Trust

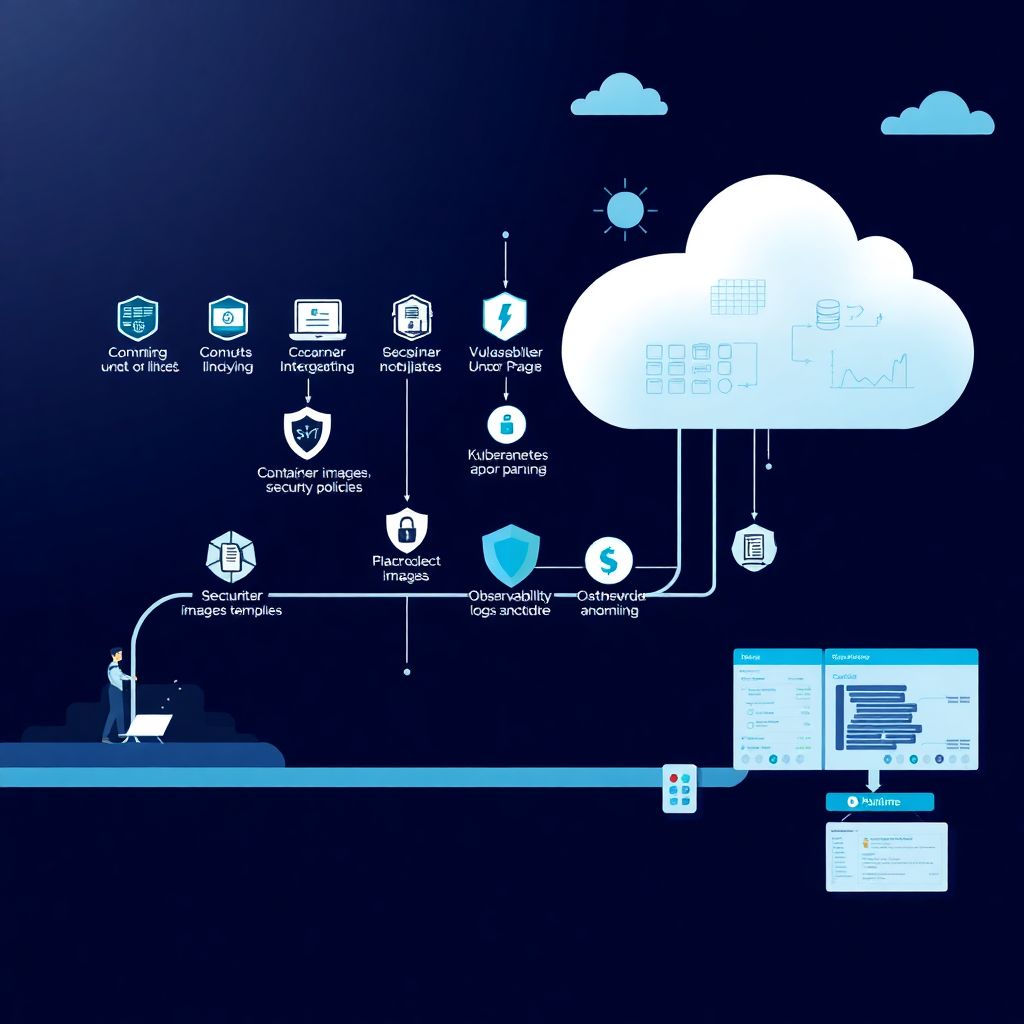
Классическая модель с отдельным отделом безопасности просто не успевает за облаком. В cloud‑среде инфраструктура меняется десятки раз в день, и ручные чек‑листы превращаются в иллюзию контроля. Гораздо эффективнее встроить правила и проверки прямо в конвейер и тем самым превратить лучшую практику в привычку. Когда вы продумываете как implementar DevSecOps em ambiente cloud, ключевая мысль проста: каждое действие разработчика, админа и системы должно автоматически оставлять за собой “след” безопасности — лог, отчёт сканера, политику доступа. Тогда доверие к релизу основано не на вере, а на данных.
Designing Your First Pipeline in the Cloud
Start Small: One Service, One Team
Самая частая ошибка — пытаться внедрить всё и сразу во всей компании. Гораздо продуктивнее выбрать один сервис, одну команду и собрать пилотный pipeline DevSecOps na nuvem вокруг их реального потока задач. Вы вместе описываете, как код попадает в прод, где уже есть слабые места, сколько времени тратится на ручные проверки. Затем добавляете минимальный набор автоматизации: скан кода при каждом pull request, проверка зависимостей при сборке, простые policy‑checks для инфраструктуры. Эта “лаборатория” даст вам живые метрики и реальные инсайты, а не теоретические слайды.
Wiring Security into Your Git Workflow
Практически всё начинается с Git. Именно сюда удобно встроить первые барьеры защиты, не перегружая людей. При каждом push вы можете автоматически запускать unit‑тесты, линтеры и базовые security‑сканеры, а при pull request — более глубокий анализ. Критично, чтобы результат был виден прямо в интерфейсе Git‑платформы: разработчик сразу видит, какая строка кода создаёт риск, и может тут же её править. Такой подход не пугает команду “большой безопасностью”, а превращает её в ещё один привычный чек перед merge, как форматирование или покрытие тестами.
From Code Scanning to Build-Time Defenses
Choosing and Tuning ferramentas de code scanning para DevSecOps
Инструменты сканирования кода сейчас есть на любой вкус, но важно не количество, а то, как вы их встраиваете. Хорошие ferramentas de code scanning para DevSecOps не просто находят уязвимости, а объясняют контекст: где входные данные, какой фреймворк, как реально может выглядеть атака. На старте логично включить готовые наборы правил для типовых ошибок вроде SQL‑инъекций и XSS, а потом постепенно дополнять их своими правилами под ваш стек. Главный практический критерий — соотношение сигнал/шум: если 90% отчётов — ложные срабатывания, разработчики быстро начнут игнорировать все алерты сразу.
Securing Dependencies and Containers
Большая часть уязвимостей сегодня прячется не в вашем коде, а в зависимостях и Docker‑образах. Поэтому в конвейере сборки стоит автоматически проверять версии библиотек и базовых образов, блокируя релизы с критичными дырами. В облаке удобно иметь “золотые” образы с минимальным набором пакетов и жёсткими настройками, которые проходят ручной аудит один раз, а потом используются повсюду. Это и есть одна из melhores práticas de segurança DevSecOps na nuvem: вы сокращаете поверхность атаки по умолчанию, не заставляя каждую команду заново изобретать безопасную конфигурацию под каждый сервис.
Shifting Security into Runtime
Observability as proteção em runtime para aplicações na nuvem

Сканирование кода и образов даёт лишь половину защиты. Вторая половина — это то, что происходит с вашим приложением под реальной нагрузкой. Хорошая proteção em runtime para aplicações na nuvem опирается на наблюдаемость: структурированные логи, метрики, трейсы. Вы видите, откуда приходят подозрительные запросы, какие эндпоинты ведут себя аномально, какие контейнеры неожиданно потребляют много CPU или открывают новые сетевые соединения. На этом слое легко строить простые, но полезные правила: блокировать запросы с явно вредоносными шаблонами, ограничивать скорость для подозрительных IP, автоматически помечать сомнительные деплои.
Automated Response Without Breaking Production
На этом этапе у команд часто возникает страх: “Если мы начнём всё автоматически блокировать, прод рухнет от ложных срабатываний”. Поэтому разумно двигаться по ступеням. Сначала вы работаете в режиме “только алерты”, собираете статистику, понимаете, какие шаблоны атак типичны именно для вашего домена. Затем переводите отдельные правила в “enforce‑режим” — например, автоматическую блокировку известных сигнатур или отключение подозрительных pod‑ов в Kubernetes. Вы всегда можете настроить “красную кнопку” для быстрого отката политики, поэтому контроль остаётся за людьми, а рутина уходит к автоматике.
Real-World Stories and Growth Paths
Startup Case: Shipping Faster with Fewer Incidents
Небольшой финтех‑стартап начал с хаотичных релизов прямо в прод, пока однажды не потерял день на расследование утечки тестовых данных. Команда не стала покупать десятки сложных решений, а сосредоточилась на простом наборе: скан зависимостей при каждом билде, статический анализ в pull request, базовый WAF перед API‑шлюзом. Через три месяца они снизили количество инцидентов безопасности почти до нуля и сократили время ревью фич. В итоге обсуждение “как implementar DevSecOps em ambiente cloud” у них превратилось не в спор про запреты, а в разговор о том, как ещё ускорить выпуск релизов без дополнительного риска.
Enterprise Case: Turning Legacy into Cloud-Native
Крупная корпорация с монолитным приложением решила переехать в облако и перейти на микросервисы. Сначала безопасность видела в этом только рост сложности, но команда архитекторов предложила иной ракурс: каждый новый сервис запускается только через единый конвейер с обязательным сканом кода, проверкой инфраструктурных шаблонов и централизованным мониторингом. Старые процессы при этом не ломали, а постепенно “подтягивали” их к новым стандартам. Через год значительная часть критичных систем уже работала в облаке, а служба безопасности впервые получила сквозную картину рисков вместо разрозненных отчётов по отдельным проектам.
How to Keep Leveling Up: Resources and Communities
Чтобы не застрять на базовом уровне, командам полезно постоянно учиться и обмениаться опытом. Онлайн‑курсы по облачной архитектуре и DevSecOps дают аккуратную теорию, но настоящее ускорение приходит, когда вы начинаете участвовать в митапах, читать разборы реальных инцидентов и смотреть, как другие компании строят свои pipeline DevSecOps na nuvem. Хороший ориентир — практические гайды от провайдеров облака, открытые репозитории с примерами конвейеров и блоги инженеров, которые честно описывают и удачи, и провалы. Так формируется внутреннее чувство, что безопасность — это не разовый проект, а постоянное движение вперёд всей команды.