Por que o seu pipeline precisa nascer com segurança embutida
DevSecOps em nuvem na vida real, não no slide do consultor
Imagine uma equipe que migrou tudo para Kubernetes em um grande provedor de nuvem, montou um CI/CD bonito e, dois meses depois, descobriu que estava publicando imagens com segredos hardcoded em variáveis de ambiente. Nada de ataque sofisticado: apenas um fork malicioso de um repositório interno vazou para um mirror público. Esse tipo de problema mostra por que um pipeline devsecops em nuvem precisa tratar segurança como parte do fluxo de entrega, não como auditoria trimestral. Se a esteira não impede o erro logo no commit ou no build, alguém em produção vai pagar a conta, geralmente em horário de plantão.
Do “funciona na minha máquina” ao “é seguro em qualquer ambiente”
O salto mental é simples de formular e difícil de praticar: tudo o que você faz para garantir qualidade também precisa ter um equivalente de segurança. Tem teste unitário? Ótimo; agora adicione escaneamento de dependências de forma tão obrigatória quanto o teste de unidade. Tem revisão de código? Traga checklist mínimo de ameaças comuns para aquele tipo de serviço. A ideia é que o desenvolvedor não precise “lembrar” de rodar ferramentas, porque o pipeline faz isso sozinho. Assim, o hábito deixa de ser boa vontade individual e vira uma rotina previsível, monitorável e auditável.
Desenhando o pipeline DevSecOps sem burocracia inútil
Comece pequeno: um estágio de segurança por vez
Um erro clássico ao pensar em como implementar devsecops no ci cd é tentar encaixar, de cara, todos os scanners possíveis e imagináveis. Resultado: builds lentos, falsos positivos por toda parte, e o time desabilita metade das verificações para “ganhar velocidade”. Uma abordagem mais madura é começar com o que causa mais dano rápido: análise de dependências, verificação de segredos e configuração básica de contêiner. Depois que isso virar rotina estável, você adiciona SAST, testes de API e checagens de infraestrutura como código. Cresça por camadas, como se fosse hardening de sistema operacional.
Separar velocidade de profundidade com pipelines em paralelo
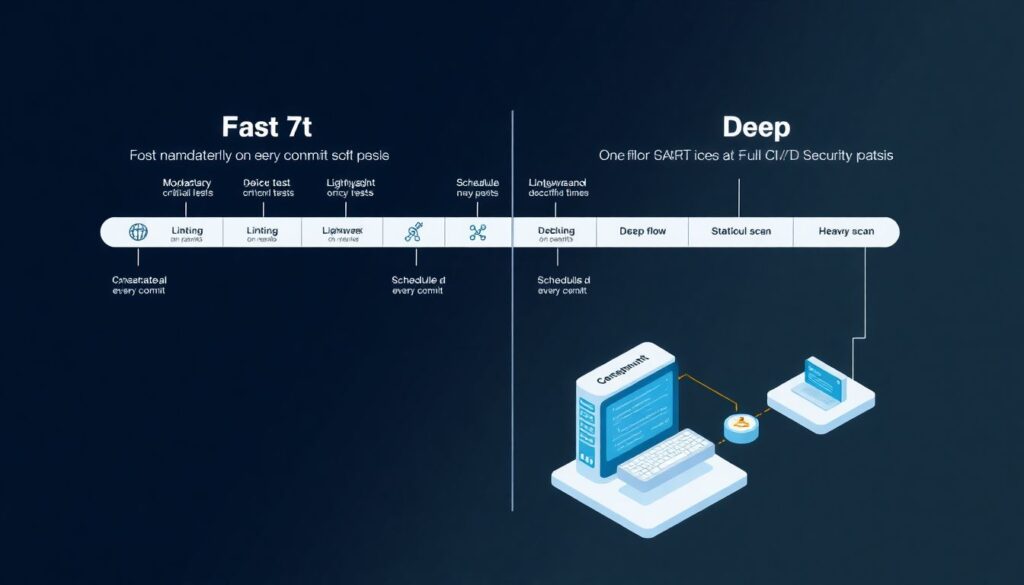
Uma solução pouco explorada é dividir o pipeline em dois fluxos: um rápido, obrigatório em todo commit, e outro mais pesado, rodando em paralelo ou em horários específicos. No fluxo rápido, você mantém o mínimo viável: lint, testes críticos e scanners leves. No fluxo profundo, executa SAST completo, varredura de IaC e análise dinâmica em ambientes de staging. Dessa forma você não sacrifica feedback rápido para o desenvolvedor, mas também não abre mão de checagens mais demoradas, necessárias para serviços expostos à internet e dados sensíveis.
Escolhendo e domando as ferramentas de segurança
Ferramentas não faltam, integração útil é que é rara
Ao montar suas ferramentas ci cd seguras para devsecops, o risco é cair na “síndrome do painel bonito”: dashboards cheios de gráficos que ninguém consulta no dia a dia. Em vez disso, priorize integrações que devolvam feedback direto para o fluxo de trabalho do time, como comentários automáticos no pull request com explicações de vulnerabilidades em linguagem de desenvolvedor. Um case real: uma fintech reduziu em 40% o tempo médio de correção quando passou a receber as recomendações de correção diretamente no PR, em vez de em um relatório semanal enviado por e-mail.
Segredos, tokens e o perigo do “só para testar”
Em praticamente todo incidente interno, em algum lugar existe um “token temporário” esquecido em repositório ou arquivo de configuração. Um truque simples e muito efetivo é tratar gerenciamento de segredos como primeira etapa de qualquer solução devsecops ci cd segurança em nuvem. Use cofres gerenciados pelo provedor de nuvem, rotação automática e políticas que impeçam variáveis sensíveis em pipelines de fork externos. Combine isso com scanners de segredos em cada commit; não para punir, mas para bloquear o erro na origem e orientar o dev sobre como usar o cofre corretamente.
Integrando segurança com a cultura do time
SLAs e “budget de risco”: o lado pouco falado
Muita gente fala de melhores práticas devsecops para aplicações em nuvem, mas pouca gente define quem decide quando uma vulnerabilidade impede o deploy. Um caminho pragmático é tratar risco como “budget” planejado: você define níveis de severidade, tempos máximos para correção e exceções documentadas. Por exemplo, vulnerabilidades críticas em serviços expostos bloqueiam o pipeline; em serviços internos, podem gerar alerta com prazo curto de correção. Tudo isso fica versionado no repositório, junto com o código, para que ninguém tenha que caçar decisões em e-mails antigos.
Tornar o time coautor das políticas de segurança
Políticas impostas de cima para baixo tendem a virar “gambiarras oficiais”. Uma abordagem mais efetiva é construir as regras junto com quem escreve o código e opera o ambiente. Traga o time para definir quais checagens entram primeiro, que mensagens de erro fazem sentido, quanto tempo de pipeline é aceitável para cada serviço. Em uma empresa de SaaS B2B, só depois de envolver engenheiros de suporte nas discussões de segurança é que o time percebeu que certos bloqueios em PR precisavam de mensagens mais claras, vinculadas a playbooks de correção, para evitar tickets desnecessários.
Automação profunda e truques de profissional
Ambientes efêmeros como laboratório de ataque controlado
Um recurso ainda subutilizado é criar ambientes efêmeros por pull request, não apenas para testes funcionais, mas para simular ataques reais de forma automatizada. Em vez de rodar só scanners estáticos, você pode acoplar pequenos scripts de fuzzing, testes de autorização e validação de headers de segurança. Como esses ambientes sobem e descem automaticamente, o custo fica controlado. Em uma empresa de mídia, isso revelou bugs de autorização em endpoints internos que nunca apareciam nos testes tradicionais, porque só surgiam com combinações específicas de cabeçalhos e cookies.
Feature flags para segurança gradual em produção
Nem toda regra de segurança precisa ser “tudo ou nada”. Com feature flags, você pode ativar gradualmente validações adicionais apenas para parte do tráfego, monitorando impacto real em métricas de erro e latência. Por exemplo, ao endurecer políticas de CORS ou de tamanho de payload, você habilita primeiro para 5% dos usuários e observa o comportamento. Essa estratégia também funciona para novos validadores de entrada, WAF gerenciado ou regras de rate limit. O pipeline orquestra a mudança e, se algo der errado, a reversão é tão rápida quanto mudar uma flag.
Medição contínua e iteração do seu pipeline
Indicadores que realmente contam a história
Não basta ter pipelines “verdes”; você precisa saber se a segurança está, de fato, melhorando. Métricas úteis incluem tempo médio para corrigir vulnerabilidades detectadas pelo pipeline, número de findings reabertos por correção incompleta e porcentagem de builds bloqueados por falhas críticas. Um insight comum: quando o número de bloqueios cai a zero de repente, muitas vezes não é porque o sistema ficou perfeito, mas porque alguém afrouxou as regras. Revisar periodicamente essas métricas em cerimônias ágeis ajuda a tratar segurança como parte do fluxo de valor, e não como ruído.
Quando faz sentido rever tudo do zero
Há momentos em que remendar o pipeline existente só aumenta a confusão. Se você acumulou anos de integrações manuais, scripts sem dono e exceções por todo lado, pode ser mais barato criar um novo fluxo padrão e migrar os serviços aos poucos. Use essa oportunidade para codificar políticas em arquivos versionados, documentar decisões e eliminar ferramentas redundantes. A cada migração, aplique lições aprendidas do serviço anterior, ajustando senso comum do time. Com isso, o pipeline deixa de ser “caixa preta do DevOps” e vira parte transparente do produto, tão importante quanto o próprio código.