Por que threat modeling em aplicações cloud-native é diferente
Cloud-native mudou o jogo. Microservices, Kubernetes, serverless, CI/CD em alta velocidade. Tudo isso é ótimo para entrega contínua — e péssimo para quem ainda faz segurança “no fim do projeto”.
Threat modeling para aplicações cloud-native precisa acompanhar essa velocidade. Não dá para passar 3 semanas desenhando diagramas que ninguém olha depois. O modelo tem que ser leve o suficiente para rodar a cada feature importante, mas profundo o bastante para achar problemas antes de entrar em produção.
Hoje, times maduros fazem threat modeling de 30 a 90 minutos por feature crítica, integrando o processo no fluxo de pull requests. E é disso que vamos falar: como fazer na prática, com modelos, checklists e exemplos de diagramas que realmente funcionam em produção.
—
Princípios práticos de threat modeling em cloud-native
1. Comece pelo que mais dói para o negócio
Não comece listando todas as portas e protocolos. Comece respondendo:
1. O que aconteceria se alguém vazasse todos os dados deste serviço?
2. E se esse serviço ficasse indisponível por 4 horas?
3. E se alguém conseguisse executar código arbitrário dentro do cluster?
Essas três perguntas já orientam onde focar o threat modeling: dados sensíveis, disponibilidade e controle de execução.
Especialistas de grandes plataformas (AWS, Google Cloud, Azure) repetem uma ideia simples: “modelar ameaças sem falar primeiro de impacto de negócio gera diagramas bonitos e pouca segurança real”.
—
2. Use um modelo simples e repetível (4 perguntas)
Para aplicações cloud-native, um fluxo de threat modeling eficiente pode ser reduzido a quatro perguntas:
1. O que estamos construindo?
2. O que pode dar errado?
3. O que estamos fazendo para mitigar?
4. O que falta validar ou automatizar?
Essa lógica funciona bem em squads ágeis porque encaixa em uma única sessão curta por feature. Você pode aprofundar com STRIDE ou outros frameworks, mas comece com isso.
—
Criando o diagrama de arquitetura certo (sem perfeccionismo)
O nível certo de detalhe
Seu diagrama não é documentação eterna. Ele é uma ferramenta para conversar sobre risco.
Inclua só três tipos de elementos:
– Componentes (services, pods, funções serverless)
– Armazenamento (bancos, filas, buckets)
– Fronteiras de confiança (redes, contas de cloud, namespaces, tenants)
Se o diagrama vira um “mapa de metrô” ilegível, corte detalhes. Um bom indicador: o time consegue entender a arquitetura principal em até 60 segundos olhando o desenho?
—
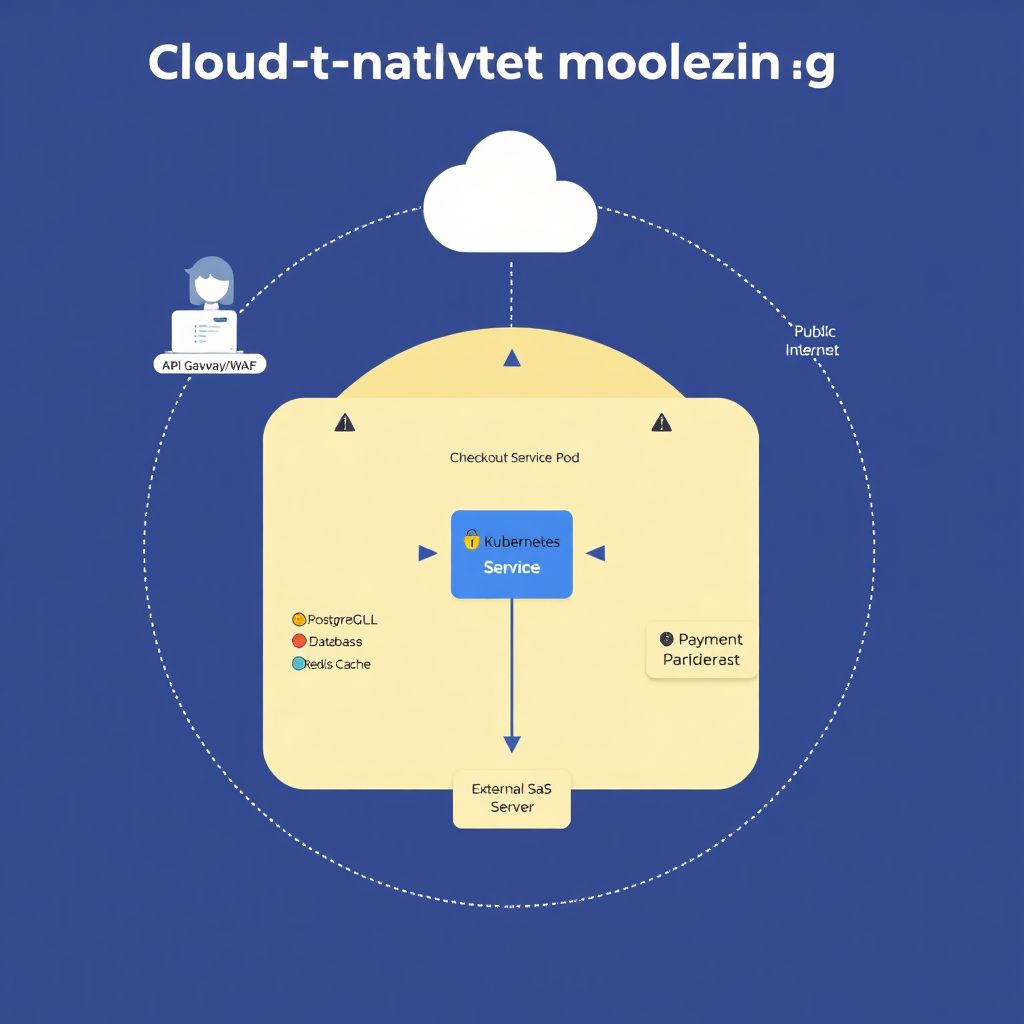
Exemplo de diagrama para uma app cloud-native simples
Imagine uma aplicação de e-commerce:
– API Gateway público (HTTPS)
– Microserviço “Checkout Service” em Kubernetes
– Banco de dados PostgreSQL gerenciado
– Serviço de pagamentos externo (Stripe, por exemplo)
– Redis para sessão
– Pipeline CI/CD implantando em um cluster EKS/GKE/AKS
No diagrama de threat modeling, você mostraria:
– Usuário → API Gateway → Ingress Controller → Service “checkout” → Pod(s)
– “Checkout” → PostgreSQL (rede privada)
– “Checkout” → Stripe (saída para a internet)
– “Checkout” → Redis (rede interna)
– CI/CD → Cluster (via kubeconfig, IAM role ou workload identity)
E traçaria:
– Uma fronteira de confiança em torno do cluster Kubernetes
– Outra em torno da VPC/subnet privada
– Uma fronteira separando o provedor de pagamentos externo
Só isso já permite enxergar ameaças como exposição de API, movimento lateral dentro do cluster, vazamento de credenciais no CI/CD.
—
Exemplo simplificado de diagrama em texto
“`text
[Client Browser]
|
v
[API Gateway / WAF] <-- Public Internet Boundary
|
v
[Ingress Controller] -- (K8s Cluster Boundary)
|
v
[Checkout Service Pod] -----> [Redis Cache]
|
+————————> [Managed PostgreSQL DB] (Private Network Boundary)
|
+————————> [Payment Provider API – Stripe] (External SaaS)
[CI/CD Pipeline] ————> [Kubernetes API Server]
“`
Você não precisa de ferramenta visual sofisticada para começar. Alguns times fazem o primeiro rascunho literalmente em um doc Markdown usando esse estilo.
—
Modelos de threat modeling que funcionam bem em cloud-native
Modelo 1: “Data-Flow + STRIDE na prática”
O clássico: diagrama de fluxo de dados + STRIDE. Em ambiente cloud-native, foque STRIDE em três áreas:
– Borda da internet (API Gateway, ingress)
– Comunicação entre serviços (service-to-service, message brokers)
– Superfície de administração (Kubernetes API, consoles de cloud, CI/CD)
Bloco técnico:
“`text
Aplicar STRIDE em cloud-native:
S – Spoofing:
– Falsificação de identidade de serviço (falta de mTLS, JWT fraco)
– Uso indevido de roles de cloud (IAM, Service Accounts)
T – Tampering:
– Manipulação de mensagens em filas não cifradas
– Alteração de imagens em registries sem assinatura
R – Repudiation:
– Logs incompletos em microservices
– Falta de correlação entre IDs de requisição
I – Information Disclosure:
– Dados sensíveis em logs
– Buckets de storage públicos por engano
D – Denial of Service:
– Serviços sem limits/requests em Kubernetes
– Fila ou broker saturando ao receber bursts
E – Elevation of Privilege:
– Containers rodando como root
– RBAC permissivo no cluster (cluster-admin “temporário” permanente)
“`
—
Modelo 2: modelo de threat modeling para aplicações em Kubernetes
Para Kubernetes vale a pena ter uma visão própria de ameaça, além do STRIDE tradicional. Um modelo prático é pensar em três camadas:
1. Cluster & Control Plane
– Acesso ao kube-apiserver
– Configuração de etcd
– RBAC, admission controllers
2. Workloads & Runtime
– Pods, deployments, jobs
– Policies (NetworkPolicy, PodSecurity)
– Sidecars (service mesh, observability)
3. Supply Chain & CI/CD
– Code repos
– Pipelines (GitHub Actions, GitLab CI, Jenkins)
– Registries de imagens
Bloco técnico:
“`text
Checklist mínimo para threat modeling em Kubernetes:
– Cluster:
– O Kubernetes API está acessível da internet?
– Existe RBAC bem definido? Quem é cluster-admin?
– Admission controller impede containers como root e privilégios excessivos?
– Workloads:
– Todos os pods têm requests/limits?
– Existe NetworkPolicy restringindo tráfego entre namespaces?
– Segredos são armazenados em Secret, KMS ou external secret store?
– Supply chain:
– Imagens são escaneadas antes de ir para produção?
– Existe assinatura de imagem (Sigstore/Cosign, por exemplo)?
– O pipeline tem acesso direto a produção? Como é controlado?
“`
Esse modelo ajuda muito em revisões rápidas de clusters novos ou ambientes multi-tenant.
—
Checklists práticos: o mínimo viável que precisa existir
Checklist de segurança focado em cloud-native
Para times começando agora, ter um checklist claro evita ficar perdido.
Um bom ponto de partida para um checklist de segurança e threat modeling para aplicações cloud é garantir pelo menos:
1. Autenticação e autorização:
– Toda API exposta exige autenticação?
– Há roles claras por tipo de usuário e serviço?
– Tokens são de curta duração (idealmente < 60 minutos)?
2. Comunicação segura:
- Todo o tráfego externo é HTTPS/TLS 1.2+?
- Service-to-service usa mTLS ou ao menos autenticação forte?
- Certificados são geridos automaticamente (ex.: cert-manager)?
3. Proteção de dados:
- Dados sensíveis em repouso usam criptografia nativa da cloud?
- Segredos (API keys, tokens) estão fora do código e do container image?
- Logs e métricas não vazam dados pessoais ou cartões (PCI, LGPD/GDPR)?
4. Deploy e runtime:
- Imagens são escaneadas a cada build?
- Containers não rodam como root e usam user não-privilegiado?
- Há limites de recursos configurados para evitar DoS interno?
5. Observabilidade e resposta:
- Logs centralizados e imutáveis (ou o mais próximo disso)?
- Alertas para acessos suspeitos (IAM, Kubernetes, banco de dados)?
- Playbooks básicos para incidentes de vazamento, DoS e ransomware?
---
Checklists em pull requests e pipelines
Um erro comum é deixar o checklist numa wiki que ninguém abre. Muito melhor:
– Colocar os itens críticos como checklist no template de pull request
– Rodar verificações automáticas no pipeline: lint de policies, scan de imagem, testes de segurança básicos
Exemplo de trechos de checklist em PR:
“`text
[ ] Esta feature introduz nova superfície exposta à internet? Se sim, descreva.
[ ] Dados sensíveis novos (Pessoais, financeiros, segredos) foram mapeados?
[ ] Threat modeling realizado (link para diagrama/comentário no doc)?
[ ] Já existem logs suficientes para rastrear ações críticas?
“`
Não é perfeito, mas força a conversa de segurança no momento certo: antes do merge.
—
Ferramentas que ajudam sem atrapalhar o fluxo do time
Escolhendo ferramentas de threat modeling para segurança em nuvem

Ferramenta não resolve falta de processo, mas ajuda a manter padrão.
Para times pequenos, uma combinação simples costuma ser suficiente:
– Documento (Confluence, Notion, Google Docs) com modelo de threat modeling
– Ferramenta de diagramas (Draw.io, Excalidraw, Miro)
– Scanners de IaC (Terraform, Helm) e imagens (Trivy, Grype) integrados ao CI
Times maiores podem avaliar ferramentas específicas de threat modeling que integram repositórios, mas cuidado para não criar burocracia que o time ignora.
Bloco técnico – critérios objetivos para escolher ferramenta:
“`text
– Integra com o repositório de código (GitHub/GitLab/Bitbucket)?
– Permite versionar os modelos junto com o código?
– Suporta templates (modelos de threat modeling reutilizáveis)?
– Permite exportar em formatos simples (Markdown, PDF, imagem)?
– Conseguimos usá-la em menos de 15 minutos de treinamento?
“`
Se a resposta para a última pergunta for “não”, provavelmente é ferramenta demais para o seu momento.
—
Exemplos reais: o que muda quando o threat modeling é feito cedo
Case 1: Falha em cache compartilhado entre serviços

Em um cliente de mid-market, um time tinha vários microservices em Kubernetes usando o mesmo Redis sem qualquer segregação. Sem threat modeling, isso passaria batido.
Durante uma sessão de 45 minutos, olhando o diagrama, alguém perguntou: “Por que o serviço de relatórios consegue ler a mesma instância Redis que guarda sessão de login?”.
Ameaça identificada:
– Se o serviço de relatórios for comprometido, o atacante lê ou altera sessões de usuários logados.
Mitigação definida ali mesmo:
– Redis separado para sessão com ACL específica
– NetworkPolicy impedindo acesso de serviços não autorizados
– Plano de migração incremental em duas sprints
Custo da correção: cerca de 3 dias de trabalho.
Custo estimado de um incidente desse tipo (com vazamento de sessão + notificação a clientes): dezenas de milhares de dólares, fora dano reputacional.
—
Case 2: CI/CD com credencial privilegiada e acesso direto ao cluster
Em outro cenário, o pipeline de CI/CD tinha um token com permissão total no cluster, armazenado como secret em texto simples no sistema de CI. Durante o threat modeling, analisando o fluxo “CI/CD → Kubernetes”, apareceu a pergunta:
– “Se alguém comprometer a conta de CI, o que consegue fazer?”
Resposta:
– “Tudo. Criar deployment, ler segredos, modificar configs.”
A mitigação acordada:
– Trocar token estático por integração OIDC / workload identity
– Reduzir permissões para apenas os namespaces necessários
– Adicionar escopos diferentes por ambiente (dev, staging, prod)
Depois disso, um pentest mostrou exatamente essa cadeia de ataque em outro time da empresa. Ter tratado o risco antes poupou uma dor de cabeça considerável.
—
Como rodar threat modeling em times ágeis, sem travar entregas
Ritual leve que funciona em squads
Um formato bastante usado por times maduros:
1. Kick-off de feature (30–40 min)
– Product Owner explica o objetivo e o fluxo principal.
– Engenheiro de software desenha o diagrama inicial.
– Engenheiro de segurança ou “champion” da squad conduz o questionamento de ameaças.
2. Documentação mínima (15–20 min)
– Preencher template simples (ameaça → impacto → mitigação).
– Atualizar diagrama com campos relevantes (ex.: “este link usa mTLS”).
3. Validação em PR
– Link para o threat model no PR principal da feature.
– Revisão de segurança foca se o que foi combinado está de fato implementado.
Total de esforço: algo entre 45 e 90 minutos por feature crítica.
Para features pequenas, muitas squads apenas verificam se a mudança impacta ameaças já mapeadas, sem sessão formal.
—
Quando vale chamar especialistas externos
Nem todo time tem alguém experiente em cloud-native. Em ambientes mais complexos — múltiplos clusters, dados sensíveis (saúde, finanças), requisitos regulatórios — faz sentido buscar apoio especializado.
Uma boa prática é trazer uma consultoria de segurança cloud native e threat modeling para:
– Ajudar a criar modelos base que o time interno reutiliza
– Treinar champions de segurança em cada squad
– Conduzir threat modeling de sistemas mais críticos (identity, billing, dados pessoais)
Depois disso, o time interno segue operando e só chama reforço para grandes mudanças de arquitetura.
—
Formação e melhoria contínua
Treinando o time sem parar o roadmap
Em vez de fazer um grande treinamento teórico de três dias, muitos times têm tido mais resultado com ciclos curtos:
– Sessões mensais de 1 hora com exemplos reais do próprio ambiente
– Revisão de um ou dois diagramas existentes, apontando melhorias
– Rodízio para que devs diferentes facilitem a sessão
Se você está estruturando seu programa interno, vale considerar um curso de threat modeling para aplicações cloud native que traga exercícios baseados em Kubernetes, APIs e CI/CD, não apenas em monolitos tradicionais.
Bloco técnico – métricas simples para avaliar maturidade:
“`text
– % de features críticas que passaram por threat modeling antes do deploy
– Tempo médio gasto por sessão (meta: < 90 minutos)
- Nº médio de ameaças relevantes encontradas por sessão
- % de ações de mitigação realmente implementadas dentro de 2 sprints
```
Esses números dizem bem mais sobre o estado real da segurança do que qualquer slide com notas de “maturidade”.
---
Fechando o ciclo: do diagrama à prática diária
Threat modeling em aplicações cloud-native não é sobre criar documentos perfeitos. É sobre tornar risco um tema de conversa rotineiro entre produto, desenvolvimento e segurança.
Se você:
– Desenha diagramas simples para cada fluxo importante
– Usa um modelo repetível (4 perguntas + STRIDE onde fizer sentido)
– Mantém um checklist enxuto e integrado ao fluxo de PR/CI
– Revisa regularmente ameaças em torno de Kubernetes, CI/CD e dados sensíveis
… já está à frente de muitos times que dependem só de scanners e testes no fim.
A partir daí, vale ir amadurecendo:
– Introduzir automatizações para políticas de cluster e IaC
– Padronizar modelos de threat modeling reutilizáveis por tipo de sistema
– Criar trilhas internas de formação e, quando fizer sentido, trazer especialistas externos
Com isso, em poucos meses, threat modeling deixa de ser um “evento especial” e vira parte natural de como o time pensa software — o que é exatamente onde queremos chegar.