Quando as equipes começam a rodar workloads em containers, quase sempre a história é a mesma: tudo parece mágico, leve, fácil de escalar… até o primeiro incidente de segurança. Um container vaza credenciais em logs públicos, uma imagem “oficial” do hub vem com um CVE crítico, ou alguém sobe um Pod privilegiado em produção “só para testar rapidinho” e abre uma porta gigante para o cluster inteiro. A boa notícia: dá para evitar a maior parte desses problemas com uma abordagem estruturada, saindo da imagem local até o ambiente de produção com scanners, políticas e proteção em tempo de execução bem amarrados. Vamos montar esse passo a passo com linguagem direta, alguns sustos reais de produção e dicas para quem está começando em segurança em containers docker kubernetes.
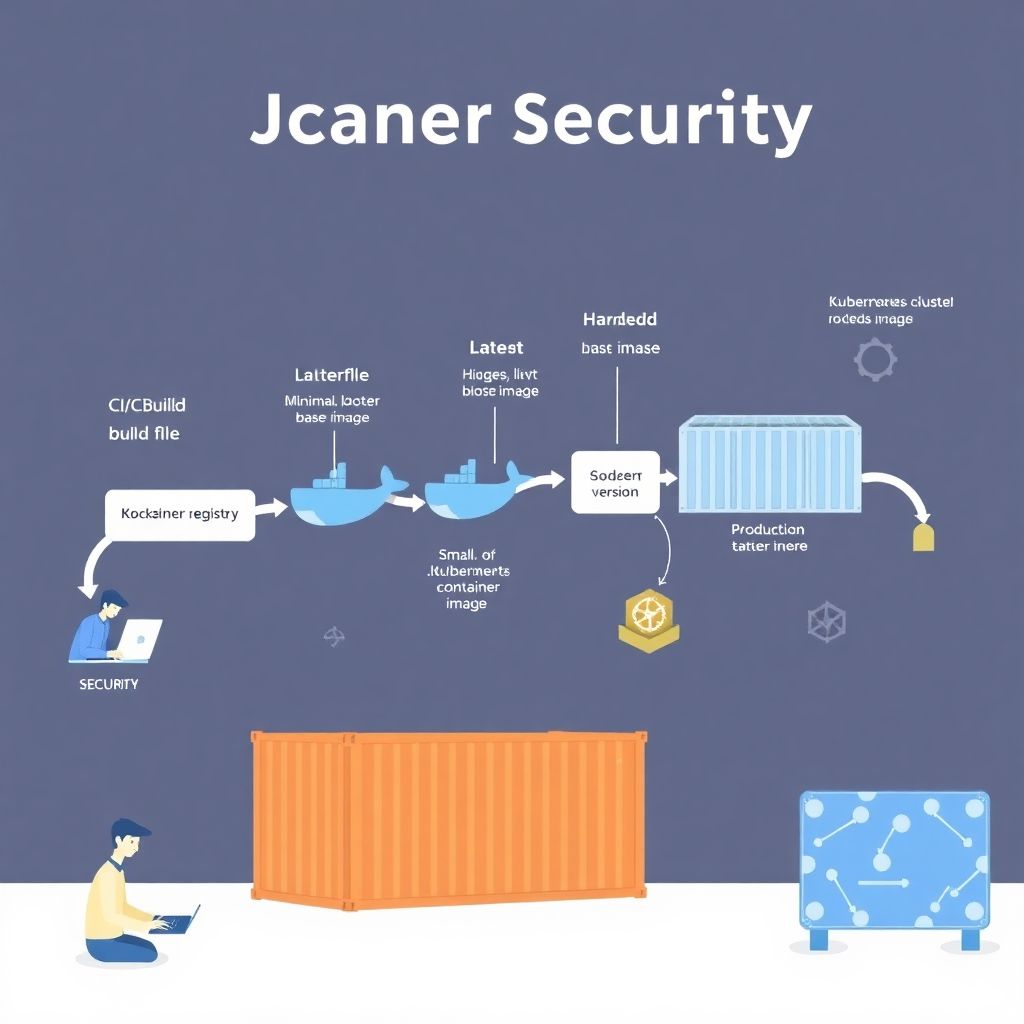
Entendendo o ciclo de vida de segurança do container: do laptop ao cluster
Antes de mergulhar em ferramentas e buzzwords, vale desenhar mentalmente o caminho de uma aplicação em container. Primeiro, alguém faz o Dockerfile e constrói a imagem; depois essa imagem vai para um registry; a seguir o CI/CD orquestra o deploy em um cluster, muitas vezes no Kubernetes ou em outra plataforma de orquestração; por fim, o container roda em produção, lidando com tráfego real. Cada uma dessas etapas abre janelas para ataques diferentes: imagens infectadas, credenciais expostas, configurações frágeis, falta de atualização de pacotes, permissões exageradas e ausência de monitoramento em tempo real. Em vez de tentar resolver tudo com uma ferramenta “milagrosa”, compensa pensar em camadas: segurança na construção da imagem, segurança no pipeline, políticas no cluster e, fechando o arco, observação e bloqueio de comportamentos estranhos enquanto os containers estão no ar.
Passo 1: construir imagens seguras sem virar refém de “imagens oficiais”
Uma das surpresas mais comuns para iniciantes é descobrir que “image: latest” ou mesmo imagens oficiais repletas de utilitários de sistema podem carregar dezenas de vulnerabilidades conhecidas. Em um caso real, uma fintech brasileira usava uma imagem oficial de linguagem de programação com mais de 1 GB, cheia de ferramentas de debug. Quando finalmente rodaram um dos principais scanners, encontraram vários CVEs críticos relacionados a bibliotecas de SSL e ao próprio sistema base. A correção não exigiu heroísmo: migraram para uma imagem minimalista, construíram uma imagem “golden” interna, com poucos pacotes e versões fixas, e passaram a usar essa base em todos os serviços. O ganho de segurança foi acompanhado de build mais rápido e deploy mais leve, mostrando que boas práticas muitas vezes também significam menos fricção técnica.
Passo 2: usar ferramentas de scanner de imagens de container como gate obrigatório

Depois de ter um Dockerfile mais consciente, entra o papel das ferramentas de scanner de imagens de container, que vão escanear bibliotecas, SO base e até configurações de runtime declaradas na imagem. Muita gente começa testando scanners apenas no laptop, mas o pulo do gato é integrá-los ao CI/CD como etapa obrigatória, com política clara: se existe vulnerabilidade crítica explorável, o build falha. Em um e‑commerce que migrou para Kubernetes, o time de segurança só melhorou de verdade quando configurou o pipeline para rodar o scanner a cada commit, com relatórios automáticos, e criou um acordo coletivo: desenvolvedores tinham liberdade para corrigir rapidamente as dependências; se não resolvessem em determinado prazo, a equipe de plataforma entrava em campo. Assim, o scanner deixou de ser “alerta que ninguém lê” e virou peça central de tomada de decisão diária.
Passo 3: alertas sobre erros clássicos na hora de escrever Dockerfiles
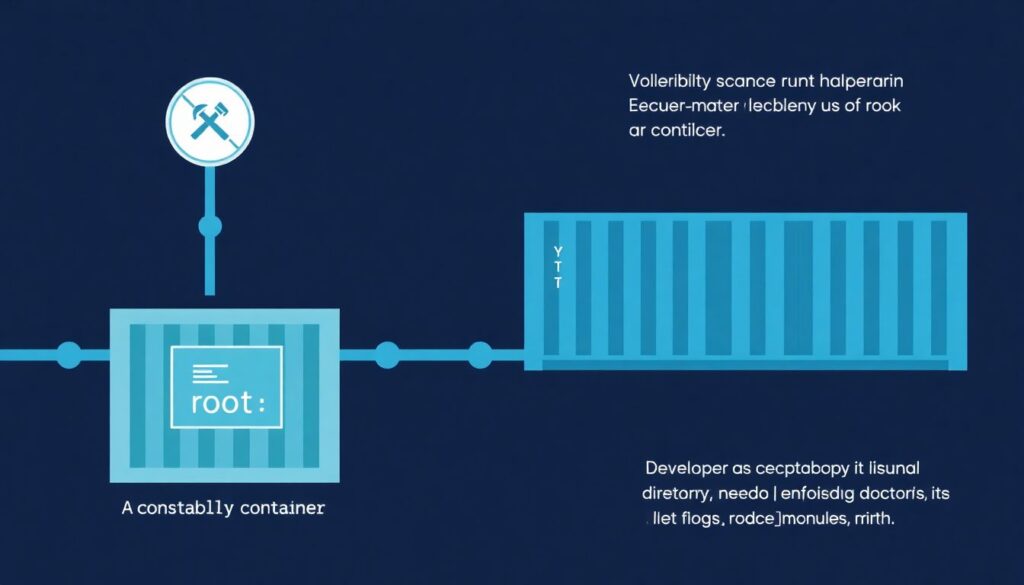
Mesmo com scanner no pipeline, alguns padrões de erro se repetem tanto que vale destacar. Um engano frequente é rodar tudo como root dentro do container, o que facilita muito a vida de um atacante caso haja fuga de isolamento. Outro tropeço é copiar o diretório inteiro da aplicação sem .dockerignore, incluindo arquivos de configuração, chaves privadas e pastas de build local, o que aumenta tanto o tamanho quanto a superfície de exposição. Para piorar, muitos ainda usam “latest” em vez de tags específicas, tornando impossível saber qual versão exata está rodando. Em uma empresa de mídia, descobriram meses depois que um container de processamento de imagens carregava um arquivo .env com segredos e tokens externos porque ninguém revisou o Dockerfile inicial com cuidado. A lição é direta: encare Dockerfile como código de produção sério, passe por review, use usuário não‑root sempre que possível e documente a intenção de cada instrução.
Passo 4: definindo políticas de segurança para containers em produção
Quando a aplicação já está pronta para ir ao ar, chega o momento das políticas de segurança para containers em produção, que vão além do que está dentro da imagem e tratam de como ela é executada. Em um cluster Kubernetes, isso significa especificar se o container pode rodar privilegiado, montar volumes sensíveis, usar capabilities de kernel, ou ter acesso à rede de forma irrestrita. Em uma empresa de saúde que lidava com dados sensíveis, a grande virada foi criar um conjunto de “policies padrão”: nenhum Pod podia rodar como root sem justificativa, sidecars que manipulavam logs tinham permissões reduzidas e existia um catálogo de tipos de volumes permitidos. Quando um time pedia exceção, era analisado caso a caso, com prazo e motivo documentados. Essa disciplina simples teria evitado vários incidents que aconteceram anteriormente, como um Pod com acesso indevido a volumes de backup por pura conveniência de desenvolvimento.
Passo 5: admission controllers, OPA e o papel das políticas declarativas
No universo Kubernetes, essas políticas ganham força real quando aplicadas por admission controllers, como o próprio PodSecurityAdmission nativo ou soluções baseadas em Open Policy Agent (OPA) e Gatekeeper. Eles atuam como porteiros: toda vez que alguém tenta criar ou alterar um recurso, o admission controller avalia a definição e decide se aprova, ajusta ou bloqueia. Um caso ilustrativo: uma empresa de SaaS permitia que times criassem namespaces à vontade. Em um fim de semana, um desenvolvedor abriu um Pod privilegiado com hostPID e hostNetwork para fazer troubleshooting, sem perceber que estava em produção. Logo depois surgiram comportamentos estranhos de rede. Após o susto, o time de plataforma implementou políticas que simplesmente recusavam Pods privilegiados, com mensagem clara de erro. Em pouco tempo, os próprios desenvolvedores começaram a sugerir melhorias nas regras, porque perceberam que aquela “burocracia” prevenia gafes que antes passavam despercebidas.
Passo 6: runtime protection para containers em kubernetes e outros orquestradores
Mesmo com imagens limpas e políticas rígidas na entrada, ainda existe a camada de runtime protection para containers em kubernetes, que observa o comportamento de processos, chamadas de sistema, uso de rede e padrões de acesso a arquivos enquanto o container está rodando. Em um ambiente de análise de dados, por exemplo, um dos clusters começou a abrir conexões suspeitas para portas de mineração de criptomoedas. Os logs não mostravam nada muito claro, mas a ferramenta de runtime sinalizou que um processo recém‑criado dentro de um container de ETL estava tentando baixar binários externos e alterar diretórios do sistema. O time conseguiu matar o Pod rapidamente e fazer análise forense. Descobriram que o problema começou com um pipeline que baixava scripts de um repositório público comprometido. Sem monitoramento em tempo real, provavelmente esse cluster teria sido usado meses como minerador, aumentando custo de nuvem e risco reputacional.
Passo 7: protegendo o registry e o pipeline, não só o cluster
Um erro silencioso é tratar o registry apenas como “lugar onde as imagens moram” e não como parte crítica da superfície de ataque. Em um caso real, um time publicou sem querer uma imagem de teste com variáveis de ambiente contendo senhas para bancos de dados internos em um registry público. Alguém descobriu pelo histórico e, felizmente, avisou de forma responsável, mas o dano poderia ter sido bem maior. O aprendizado foi configurar regras de acesso estritas ao registry, ativar scan automático de cada push e ativar limpeza programada de imagens antigas, reduzindo a chance de lixo sensível ficar esquecido. Além disso, o pipeline de CI passou a usar credenciais de curta duração, renovadas automaticamente, em vez de tokens estáticos mantidos em repositórios. Esse cuidado garante que ferramentas de scanner de imagens de container e mecanismos de deploy atuem em um ambiente minimamente controlado, sem virar porta de entrada para invasores pacientes.
Passo 8: soluções de segurança para containers em nuvem e o risco da falsa sensação de proteção
Muitos times apostam forte em soluções de segurança para containers em nuvem fornecidas pelos próprios provedores, achando que isso resolve tudo automaticamente. Esses serviços de fato ajudam com visibilidade, integração com identidade, logs centralizados e alguma automação, mas não substituem desenho de arquitetura cuidadoso. Uma empresa que migrou às pressas para a nuvem habilitou o serviço de segurança gerenciado e achou que estava coberta; meses depois, descobriram que vários clusters rodavam sem autenticação forte no painel de administração, simplesmente porque o time assumiu que “a ferramenta do provedor cuida disso”. O que faltou foi um mapeamento claro de responsabilidades: o que o provedor garante e o que continua 100% nas mãos da equipe? Em cloud, segurança é um jogo de corresponsabilidade; as ferramentas são aliadas, mas continuam dependendo de políticas bem definidas e operadores atentos, especialmente quando o assunto é produção crítica.
Checklist prático: passos numerados para quem está começando
Para transformar tudo isso em ação, compensa organizar um plano enxuto, algo que dê para executar em algumas iterações, sem tentar abraçar o mundo de uma vez. Uma abordagem realista, usada por muitos times que estão amadurecendo segurança em containers docker kubernetes, é priorizar aquilo que traz maior redução de risco com menor atrito inicial, e depois avançar para controles mais sofisticados. Assim, em vez de instalar dez ferramentas e perder-se em dashboards, o time foca em estabilizar a base: imagens enxutas, scanners bem configurados, políticas mínimas no cluster e um monitoramento de runtime ao menos em modo observação. Essa cadência ajuda tanto equipes pequenas quanto grandes a evitarem o caos de iniciativas desconectadas que nunca se consolidam.
1. Comece revisando Dockerfiles e migrando imagens para bases minimalistas, eliminando pacotes desnecessários e definindo usuario não‑root por padrão.
2. Integre pelo menos um scanner de imagem no CI/CD, com política de falha para vulnerabilidades críticas e relatórios acessíveis aos desenvolvedores.
3. Configure um registry privado com controle de acesso, scan automático e limpeza programada de imagens obsoletas.
4. No Kubernetes, habilite admission controllers e crie um conjunto básico de políticas: proibir Pods privilegiados, exigir recursos de CPU/memória e impedir uso de “latest”.
5. Habilite uma solução de runtime que, no início, apenas observe o comportamento e gere alertas; depois, passe a bloquear ações claramente maliciosas.
Dicas para iniciantes e armadilhas que valem um alerta em letras maiúsculas
Quem está começando tende a cair em armadilhas bastante previsíveis. Uma delas é acreditar que só porque o container é efêmero, o risco é baixo: na prática, basta alguns segundos para extrair segredos, movimentar‑se lateralmente ou implantar malware. Outra ilusão comum é supor que imagens “oficiais” são automaticamente seguras, quando, na verdade, muitas delas carregam dependências desatualizadas. Um cuidado valioso é envolver o time de desenvolvimento desde cedo, explicando o porquê das regras em linguagem acessível e usando os próprios incidentes internos (ou de mercado) como exemplo. Em uma startup de logística, o time de segurança fez uma espécie de “roda de histórias de horror” mostrando incidentes reais de containers mal configurados; o clima era leve, quase de conversa de corredor, e isso ajudou a quebrar resistência. Quando as políticas começaram a ser aplicadas, poucos reclamaram, porque já sabiam qual problema cada regra se propunha a evitar.
Fechando o ciclo: segurança como processo contínuo, não como projeto pontual

No fim das contas, a proteção de containers não é um item que se configura uma vez e esquece; ela acompanha o próprio ciclo da aplicação e da infraestrutura. As vulnerabilidades de hoje não serão as mesmas de daqui a seis meses, as bibliotecas mudam, as práticas de ataque evoluem, novos recursos do orquestrador surgem, e tudo isso exige ajustes constantes. Em vez de encarar scanners, políticas e mecanismos de observação como obrigação chata, faz mais sentido enxergá‑los como rede de proteção que permite ao time inovar sem andar permanentemente no fio da navalha. Ao montar um pipeline onde imagens são avaliadas desde o build, passam por gates de política na entrada do cluster e seguem monitoradas em produção, a equipe reduz a necessidade de “apagões de incêndio” e ganha liberdade para experimentar. Segurança em containers deixa de ser um freio e passa a ser o trilho que mantém o trem na direção certa, do primeiro Docker build ao tráfego pesado em produção.