Why cloud incident response had to change

Back in the early 2010s, incident response in the cloud still looked a lot like on‑prem: tickets, war rooms, people copy‑pasting commands. As AWS Lambda, Google Cloud Functions and Azure Functions took off around 2016–2020, the number of services, accounts and regions exploded, while teams stayed the same size. By 2026, manual runbooks simply couldn’t keep up with the volume and speed of attacks. That’s where automação de resposta a incidentes em cloud soar comes in: using SOAR, serverless functions and Infrastructure as Code to turn human runbooks into codified, repeatable workflows that react in seconds instead of hours.
Key concepts, in plain but precise terms
SOAR (Security Orchestration, Automation and Response) is the “brain” that ingests alerts, enriches them, makes decisions and kicks off actions. Think of it as an automation‑first SOC platform that talks to your SIEM, ticketing, cloud APIs and messaging tools. Lambda/Functions are the “hands”: small pieces of code that do one thing well, like isolating an EC2 instance or revoking a token. Infrastructure as Code (IaC) is the blueprint, describing your security stack and playbooks as versioned code. Combined, they let you standardize soluções de segurança cloud com infraestrutura como código instead of relying on tribal knowledge and ad‑hoc shell scripts.
SOAR in the cloud era
Traditional SOAR started as heavy, on‑prem appliances wired into firewalls and IDS devices. Around 2018–2022, vendors re‑architected into SaaS‑first platforms with native cloud connectors. In 2026, a typical plataforma de orquestração e automação de incidentes em nuvem exposes: a REST API and event bus, visual and code‑based playbooks, connectors for major clouds, and role‑based access controls so SecOps, DevOps and compliance can share workflows safely. Compared with home‑grown scripts or simple SIEM rules, SOAR provides stateful workflows, error handling, approval steps and metrics, turning incident response from “best effort” into an engineered pipeline.
Serverless functions as the execution engine
Serverless changed how we execute response actions. Instead of long‑running bots, you deploy tiny Lambdas or Functions that spin up on demand, run for a few seconds and vanish. ferramentas soar para aws lambda e funções serverless make this connection trivial: the SOAR platform calls a function URL or publishes to a queue, and the function talks to the cloud control plane. This model scales with your incident volume, stays cheap when idle, and keeps blast radius low, because each function can have very narrow IAM permissions tailored to a single step like “quarantine instance” or “snapshot disk.”
Infrastructure as Code for repeatable security
IaC isn’t just for VPCs and databases anymore. By 2026, mature teams define their security automations as code too: queues, topics, IAM roles, logging, even SOAR connectors. This gives you git history, pull‑request reviews and automated testing around your incident workflows. When you treat response logic as a versioned artifact, you can roll back a broken playbook safely, or promote it from staging to prod using the same pipeline as your apps. Over time this shifts incident response from “artisanal” scripts to governed engineering, aligning security and platform teams around shared tooling.
Reference architecture: wiring it all together
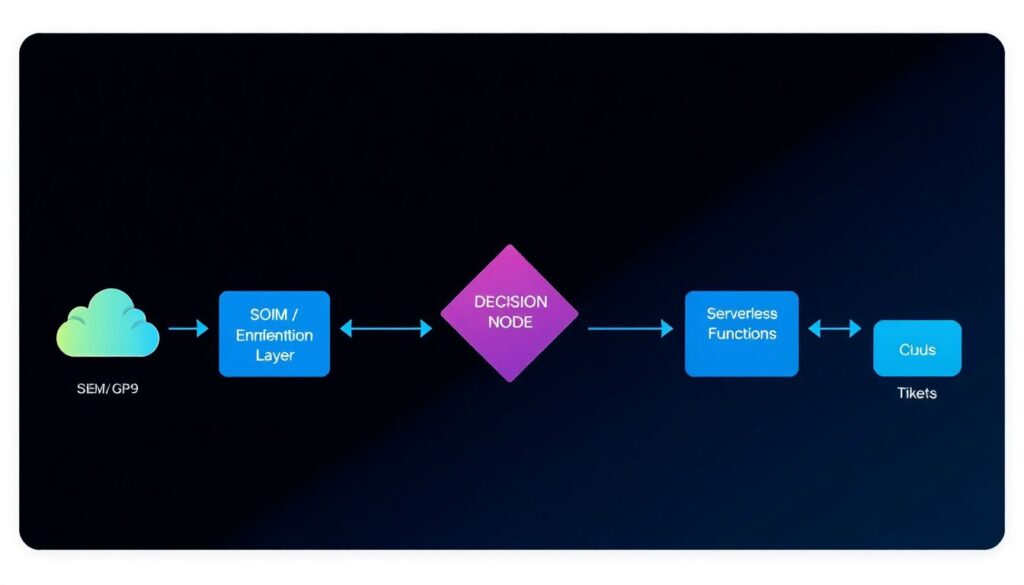
To visualize a typical setup, imagine the following data flow: [Diagram: Cloud Providers (AWS / GCP / Azure) → SIEM / Cloud-native logs → SOAR Ingestion Layer → Correlation & Enrichment Engine → Decision Node (auto / semi-auto) → Serverless Functions (Lambda / Cloud Functions) → Cloud APIs / Tickets / ChatOps]. Detection might start in a cloud‑native security tool, feed into your SIEM, then into SOAR. The SOAR workflow enriches with asset inventory, threat intel and IAM data before deciding whether to auto‑remediate via a function or request human approval in Slack, with all steps logged for auditing.
Playbooks and concrete examples
Let’s take a classic scenario: publicly exposed S3 bucket or storage bucket. A detection rule fires, SOAR receives the alert, pulls metadata (owner team, tags, business criticality), and checks if it’s in an approved exception list. If not, it calls a Lambda that locks down permissions, triggers a snapshot, and posts a message to the owning team’s chat channel. With implementação de playbooks soar com iac terraform e cloud functions, you declare queues, topics, IAM bindings and even the function triggers in Terraform, ensuring every environment (dev, test, prod) runs the same response logic, with differences captured as variables instead of ad‑hoc tweaks.
Common automated playbooks in 2026
– Credential abuse: auto‑revoke keys, kill sessions, and push a mandatory password reset.
– Suspicious compute behavior: isolate VM/container, capture memory or logs, then open a case.
– Data exfiltration: throttle or block egress, snapshot buckets, and escalate to the privacy team.
Over time, teams tune these playbooks to include risk‑based logic, so low‑risk events remain fully automated while high‑impact ones require a single click from an on‑call engineer.
How this compares to older approaches
Before SOAR and serverless, many teams relied on SIEM correlation rules plus a jungle of Python scripts on a “SOC utility box.” That worked for a while but struggled with scale, multi‑cloud coverage and reliability. Modern automação de resposta a incidentes em cloud soar centralizes logic, enforces auditability and uses cloud‑native building blocks instead of snowflake servers. Compared with pure CSPM or CNAPP tools that only offer canned remediations, a SOAR‑centric design lets you orchestrate across identity, SaaS apps, endpoints and cloud platforms, reflecting your actual business processes rather than what a single vendor decided to ship.
Practical tips and pitfalls
– Start with noisy, well‑understood incidents (like key leakage) before automating rare edge cases.
– Always build “human‑in‑the‑loop” modes first, then progressively remove approvals as confidence grows.
– Treat SOAR and functions like any other production code: tests, linting, CI/CD and monitoring.
The biggest anti‑pattern in 2026 is over‑automation without guardrails. Misconfigured playbooks can lock out entire teams, shut down critical services or delete evidence. Use scoped IAM roles, time‑boxed actions (e.g., temporary isolation) and clear rollback steps to manage this risk while still reaping the benefits of high‑speed response.
Looking forward from 2026
The historical arc from manual tickets to fully automated pipelines took barely a decade, and it’s still accelerating. LLM‑based assistants are starting to draft playbooks, explain incidents in natural language and simulate attack paths before you deploy changes. Yet the core building blocks remain the same: a robust plataforma de orquestração e automação de incidentes em nuvem, small serverless functions that enact decisions, and IaC wiring it all together in a deterministic way. Teams that invest now in clean architectures, high‑quality playbooks and shared ownership across security and platform engineering will be the ones handling tomorrow’s incidents calmly, even as cloud complexity keeps rising.