Por que vale a pena se preocupar com vulnerabilidades em cloud logo no começo
Quando a gente move tudo para cloud e containers, normalmente pensa em escala, custo, tempo de entrega. Segurança entra, na melhor das hipóteses, como “checagem final” antes de ir para produção. Só que hoje isso é receita perfeita para incidente sério.
Workloads cloud — functions, containers, pods em Kubernetes, jobs serverless — mudam o tempo todo. Se você não encaixa scanners de vulnerabilidades direto no CI/CD, você só está “congelando” risco em produção mais rápido.
A boa notícia: dá para montar um pipeline devsecops com ferramentas open source de análise de vulnerabilidades sem explodir o tempo de build, nem depender de um exército de especialistas em segurança. E dá para fazer isso de forma criativa, indo além do “roda um scanner e pronto”.
Vamos entrar no detalhe, com casos reais, truques não óbvios e alguns caminhos alternativos que pouca gente tenta.
—
Panorama rápido: o que realmente precisamos escanear
Antes das ferramentas, é útil pensar em “camadas” de risco nos workloads cloud:
– Imagens de container e pacotes do sistema
– Dependências de aplicação (bibliotecas, frameworks)
– Configuração de Kubernetes (manifests, Helm charts, Kustomize)
– Infraestrutura como código (Terraform, CloudFormation, etc.)
– Configuração da própria cloud (IAM, redes, storage)
– Runtime: o que o container realmente faz em produção
As melhores ferramentas open source para segurança em workloads cloud não focam só em uma camada. O jogo é combinar várias delas, sem virar um Frankenstein impossível de manter.
—
Ferramentas open source para scan de vulnerabilidades em cloud: o “arsenal básico”
Imagens e pacotes: a linha de frente
Aqui entram os clássicos:
– Trivy (Aqua Security)
– Grype (Anchore)
– Clair (CoreOS/Quay, hoje na CNCF)
Todos fazem varredura de vulnerabilidades em imagens de container, pacotes e, em alguns casos, repositórios de código. O Trivy, em especial, virou praticamente o canivete suíço da área.
Uma forma natural de usar: rodar o scanner na etapa de build da imagem. Mas dá para ir além, já chego lá.
—
Kubernetes e containers: não é só CVE
Quando alguém fala em scanner de vulnerabilidades open source para kubernetes e containers, normalmente pensa só em CVEs. Porém, boa parte dos problemas graves vem de configuração errada, não de falha de software em si.
Ferramentas úteis:
– kube-bench – checa compliance com benchmarks CIS
– kube-hunter – tenta “atacar” seu cluster para achar exposições
– kube-score – revisa manifests e dá recomendações (requests/limits, probes, etc.)
– Polaris (Fairwinds) – análise de boas práticas em deployments
Essas ferramentas não substituem o scanner de imagem, mas enxergam riscos que o scanner não vê: pods privilegiados, hostPath perigoso, secrets expostos e por aí vai.
—
IaC e configuração de cloud: evitar bomba-relógio
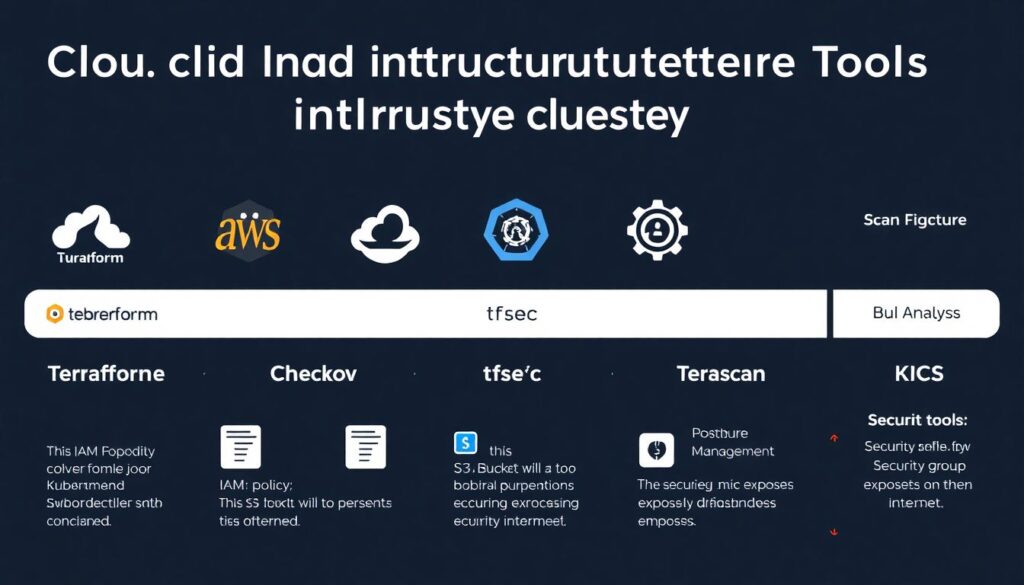
Para Terraform, CloudFormation, Kubernetes YAML, etc.:
– Checkov
– tfsec
– Terrascan
– KICS
Eles olham arquivos estáticos e avisam: “esta regra IAM está ampla demais”, “este bucket vai ficar público”, “este security group abre tudo para o mundo”.
Aqui entram também as ferramentas focadas em postura de cloud (Cloud Security Posture Management, CSPM) open source ou community, mas vamos manter o foco no que dá para plugar direto no CI/CD.
—
Como integrar varredura de vulnerabilidades open source no CI CD sem quebrar tudo
Vamos falar da parte prática: você quer que essas ferramentas rodem em cada merge/push, mas sem transformar a pipeline em um pesadelo lento e cheio de falsos positivos.
Exemplo direto com GitHub Actions (podia ser GitLab CI ou Jenkins)
Um fluxo clássico:
1. Rodar linter e testes
2. Buildar imagem
3. Rodar scanner de vulnerabilidades na imagem
4. Rodar scan de IaC e manifests
5. Deploy (se passou nas etapas anteriores)
A sequência pode parecer óbvia, mas a questão é COMO você integra:
1. Fail-soft no começo, fail-hard depois
– Nas primeiras semanas, configure o scanner para apenas comentar no PR ou mandar alerta, sem falhar o pipeline.
– Depois de limpar o backlog de vulnerabilidades, aí sim mude para quebrar o build quando aparecer algo crítico.
2. Política clara de severidade
– Por exemplo:
– Falhar build com CVEs *Critical* e *High*
– Apenas notificar sobre *Medium* e *Low*
– Isso evita parar a pipeline por causa de risco quase teórico.
3. Scan incremental
– Em vez de escanear tudo sempre, compare a imagem ou o repositório com a última versão aprovada.
– Alguns scanners e integrações conseguem rodar só em pastas alteradas, o que acelera bastante.
Esse tipo de abordagem responde, na prática, à questão de como integrar varredura de vulnerabilidades open source no ci cd sem perder a agilidade.
—
Caso real 1: startup que parou de “caçar CVE” e começou a grudar segurança no negócio
Uma startup de SaaS rodando em Kubernetes no GKE estava usando apenas Trivy no build. Resultado:
– Milhares de alertas no começo
– Time de dev bloqueado por semanas
– Um “mutirão” de segurança que ninguém queria repetir
Mudança de estratégia:
– Travaram versões de imagens base (alpine, debian) em uma lista reduzida.
– Criaram um job noturno de atualização de imagens base + scan completo dessas bases.
– Nas pipelines de app, o scanner ficou responsável só por:
– Dependências de aplicação
– Configuração de container (usuário root, capabilities, etc.)
O pulo do gato: eles mudaram o foco do scanner de “tudo o tempo todo” para “pegar o que realmente muda a cada PR”. O backlog de CVEs caiu em poucas semanas, sem precisar editar meio mundo de código.
—
Caso real 2: grande empresa com ambientes regulados e CI/CD travado pelo medo
Uma empresa de serviços financeiros tinha pipelines GitLab CI muito lentas por causa de dezenas de scanners, inclusive proprietários. Demoravam 40–60 minutos por merge. O time de devsecops virou inimigo público.
A solução foi contraintuitiva: remover scanners do CI/CD.
O que fizeram:
– Deixaram no CI apenas:
– Scan rápido de IaC (Checkov)
– Scan de imagem com severidade filtrada (Trivy)
– Moveram varreduras mais pesadas (SAST profundo, DAST, CSPM etc.) para pipelines assíncronas por branch:
– Rodavam em paralelo, fora do fluxo de merge.
– Se achassem algo crítico, abriam automaticamente um ticket ou PR com correção sugerida.
Resultado:
– CI principal caiu para menos de 15 minutos.
– Segurança continuou forte, mas com foco em risco real (crítico/alto), não em listas intermináveis de recomendação genérica.
Esse é um exemplo de alternativa útil quando “mais scanners” claramente não é a resposta.
—
Nãos óbvios: estratégias pouco exploradas que funcionam muito bem
1. Escanear a imagem base antes do seu time de desenvolvimento
Em vez de cada pipeline rodar um scan completo da imagem final, você pode:
– Definir algumas poucas imagens base oficiais internas (por linguagem/stack).
– Ter uma pipeline separada que:
– Atualiza pacotes dessas bases regularmente
– Roda scan pesado nelas
– Só publica as bases se passarem no critério de segurança
Assim, as pipelines dos apps:
– Herdam essas bases “limpas”
– Precisam escanear apenas camadas de aplicação e dependências
Isso reduz o ruído e acelera builds. E, bônus: força padronização tecnológica.
—
2. Usar SBOM como contrato de segurança
Ferramentas como Syft geram um SBOM (Software Bill of Materials) para cada build. Esse SBOM descreve tudo que está na imagem ou artefato.
Fluxo interessante:
– CI gera SBOM + roda scanner baseado em SBOM.
– SBOM é versionado junto com o release.
– Um serviço separado (pode ser open source também, tipo Dependency-Track) monitora novas vulnerabilidades relacionadas aos componentes daquela SBOM.
Isso permite que você descubra que um release antigo ficou vulnerável HOJE, mesmo que a build tenha sido “limpa” quando foi criada. Muita gente ignora esse ponto.
—
3. Inverter a lógica: varrer PR antes mesmo de buildar
Outra jogada:
– Rodar ferramentas de IaC, lint de Dockerfile e análise de manifesto Kubernetes em hooks de PR.
– Só buildar a imagem se essa checagem inicial passar.
Não parece revolucionário, mas muda a psicologia:
– O desenvolvedor corrige problemas de segurança enquanto ainda está com o contexto fresco.
– Você evita gastar tempo de build em algo que vai falhar no fim.
Ferramentas como Checkov, kube-score e Trivy (modo filesystem) rodam muito bem nessa camada.
—
Alternativas pouco lembradas (mas muito úteis)
Runtime: eBPF e monitoração comportamental
Em vez de só checar a “receita” (image, YAML, Terraform), dá para olhar o que o container faz em produção:
– Ferramentas baseadas em eBPF (como Falco e outros projetos) conseguem detectar:
– Acesso suspeito ao filesystem
– Processos estranhos rodando
– Execução de shell dentro de containers
Esses sinais não substituem o scan estático, mas ajudam a pegar exploração de vulnerabilidades que passaram nos scanners.
—
Contêiner de “polícia” no cluster
Um truque simples:
– Rodar periodicamente um job em Kubernetes que:
– Lista todas as imagens em uso no cluster
– Escaneia essas imagens em background
– Compara o resultado com uma política de risco
Se encontrar imagens com CVEs críticos, pode:
– Marcar os deployments com label de “at risk”
– Abrir PR com atualização de imagem
– Acionar um alerta no Slack/Teams
Isso cobre o caso em que alguém bypassou o CI oficial ou usou imagem manualmente no cluster.
—
Apostar em políticas como código (OPA / Kyverno)
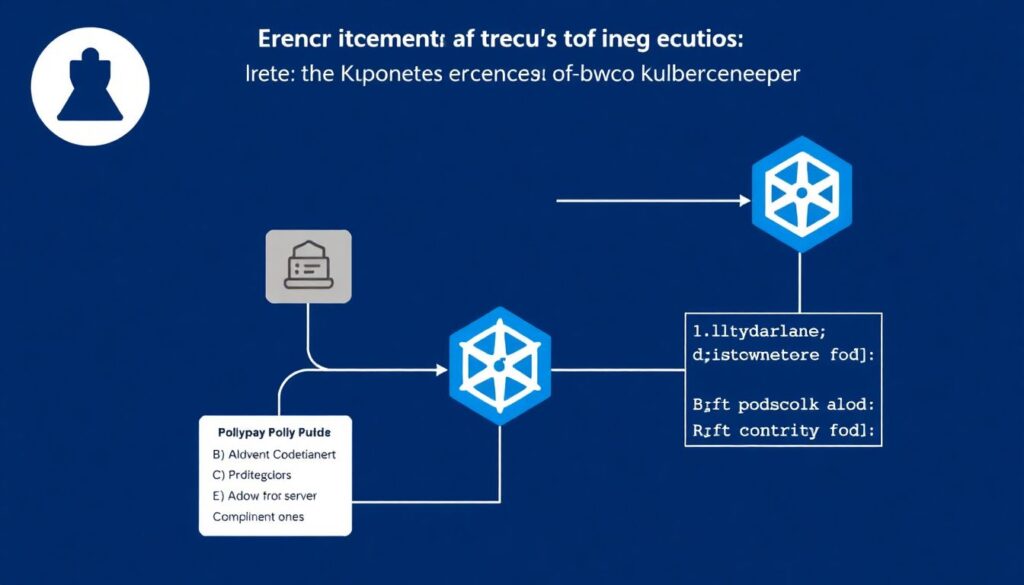
Em vez de confiar apenas em scanners que apontam problemas, você pode:
– Traduzir recomendações em políticas explícitas (ex.: “não permitir containers privilegiados”, “todos os pods devem ter resource limits”).
– Aplicar essas políticas no admission controller do Kubernetes (OPA Gatekeeper, Kyverno).
Assim, coisas inseguras simplesmente não entram no cluster, mesmo que alguém tenha ignorado um alerta de scanner.
—
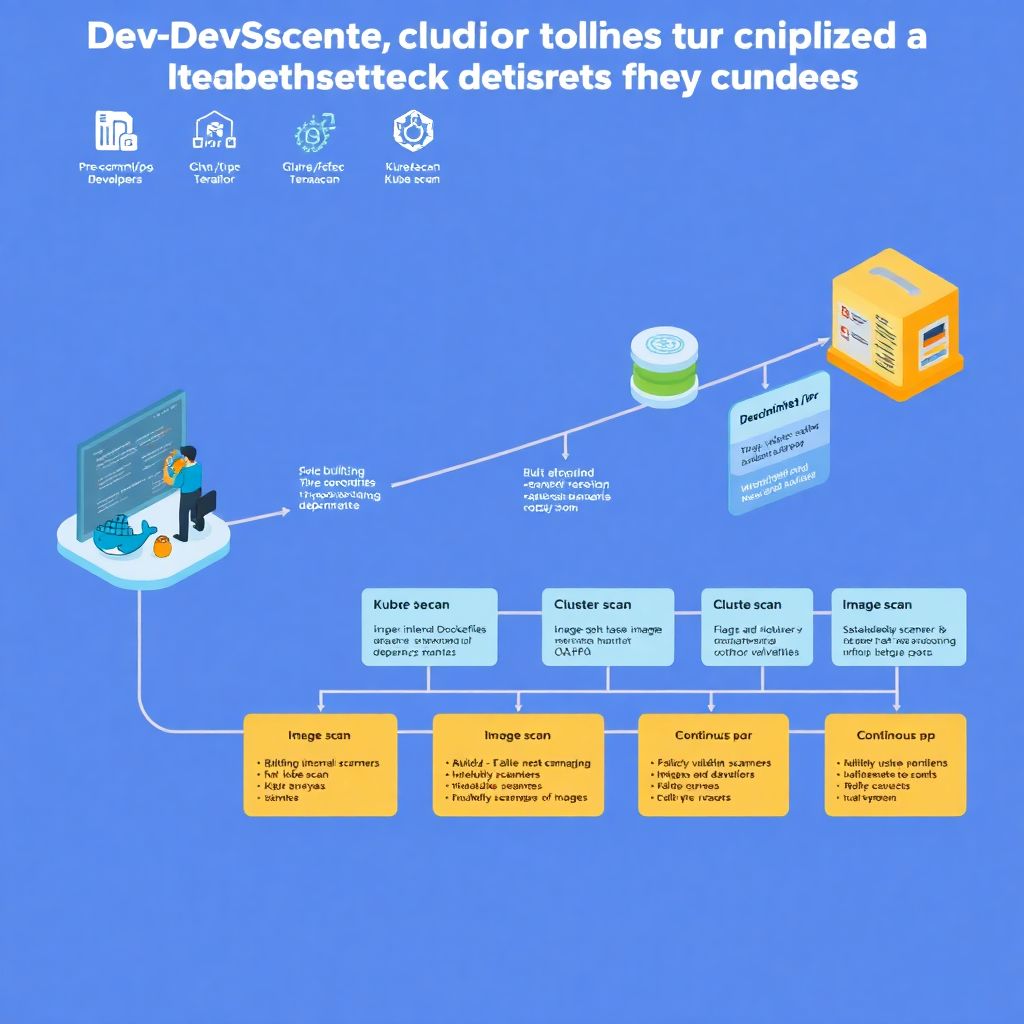
Trilha prática: montando um pipeline devsecops com ferramentas open source de análise de vulnerabilidades
Um fluxo possível (e bem pé no chão):
1. Pré-commit / PR
– Lint de Dockerfile (Hadolint)
– Scan de IaC (Checkov/tfsec)
– Análise de manifests Kubernetes (kube-score/Polaris)
2. Build
– Build da imagem com base oficial interna
– Geração de SBOM (Syft)
3. Scan de imagem e dependências
– Trivy ou Grype rodando sobre a imagem gerada e/ou SBOM
– Critérios:
– Falha em CVE Critical/High
– Aviso em Medium/Low
4. Scan de cluster (job agendado)
– kube-bench para CIS
– kube-hunter ou ferramentas similares em ambiente de staging
– Job de “polícia de imagens” rodando scans periódicos
5. Runtime
– Falco ou solução eBPF monitorando comportamento
– Alertas integrados em canal de incidentes
6. Pós-deploy e contínuo
– Pipeline assíncrona reescaneando releases antigos quando surgir CVE nova relevante
– Ajuste periódico de políticas conforme o que é encontrado
Esse modelo é modular: você começa com 1–3, e vai adicionando 4–6 conforme o time amadurece.
—
Lifehacks para profissionais que já fazem o básico
1. Gamifique segurança no time de dev
Em vez de só mandar relatórios chatos:
– Crie um dashboard com:
– Tempo médio para corrigir CVEs críticos
– Top times com menos vulnerabilidades abertas
– Use esse painel em reuniões de sprint como indicador de qualidade, não só de “compliance”.
Mais eficaz do que ameaças de auditoria.
—
2. Faça “safelist” e não “blocklist” de imagens
Ao construir política de uso de imagens:
– Liste explicitamente:
– Registries permitidos
– Imagens base aprovadas
– Bloqueie TODO o resto no admission controller.
Isso evita a proliferação de imagens aleatórias da internet, sem ter que ficar correndo atrás de cada caso estranho.
—
3. Combine scanners para reduzir falsos positivos
Nenhum scanner é perfeito. Um truque:
– Use um como “oficial” (ex.: Trivy) e outro como “validador” em pipeline paralela (ex.: Grype).
– Se uma vulnerabilidade aparece em só um deles e com severidade menor, trate como menos urgente.
– Se aparece em ambos como crítica, é prioridade máxima.
Isso ajuda a priorizar, sem precisar ler manualmente cada alerta.
—
4. Encapsule scanners em ações reutilizáveis
Em vez de copiar cola de YAML em todos os repositórios:
– Crie:
– Uma GitHub Action interna
– Um template de job do GitLab CI
– Ou uma libraria de Jenkins shared library
– Coloque dentro:
– Execução do scanner
– Config de política padrão
– Formatação de saída (por exemplo, em SARIF para uso em dashboards)
Depois, cada repositório só “consome” essa action/template. Atualizar política ou versão da ferramenta vira questão de mudar um único lugar.
—
5. Use ambientes efêmeros de teste de segurança
Para testes mais agressivos (como kube-hunter, DAST, scanners de porta, etc.):
– Suba um ambiente de preview efêmero por PR (namespace ou cluster temporário).
– Rode os testes de segurança mais intrusivos aí.
– Destrua o ambiente depois.
Assim você não precisa ter medo de rodar testes “meio mal educados” no cluster de staging compartilhado.
—
Conclusão: faça menos, só que melhor — e automatizado
Ferramentas open source para scan de vulnerabilidades em cloud não são o problema. O problema é usá-las como se fossem checklist estático, fora do fluxo de desenvolvimento.
Quando você:
– Integra os scanners logo no começo do CI/CD,
– Centraliza imagens base e SBOMs,
– Aplica políticas como código,
– E aceita que nem tudo precisa acontecer síncronamente no merge,
você deixa de “caçar CVEs” e passa a tratar segurança como uma propriedade natural do seu pipeline.
O segredo não é empilhar scanners, mas montar um desenho inteligente, com algumas peças muito bem posicionadas. E aí, sim, suas ferramentas open source deixam de ser barulho e começam a trabalhar a seu favor.