
Historical context of container and image vulnerability analysis
Back when Docker was still a novelty, most teams treated containers as just another packaging format and barely thought about attack surfaces. Around 2015–2018, the main focus was on securing the host and maybe adding a basic scanner de vulnerabilidades para imagens docker right before pushing to production. As Kubernetes exploded, people realized that container images behave more like immutable building blocks than traditional app bundles, and leaving them unchecked meant quietly shipping known CVEs into fleets of nodes. Regulators and auditors also woke up: financial and healthcare organizations started to ask specifically how images were scanned, how exceptions were tracked and what evidence teams could produce during a security review or incident root-cause analysis.
Between 2019 and roughly 2023, “shift-left” became the slogan, but the practice was inconsistent. Some companies ran ad‑hoc scans in CI; others relied on a weekly script pulling images from registries and dumping reports no one really read. The turning point came with supply‑chain attacks and SBOM requirements: suddenly, knowing exactly which vulnerable libraries were inside each image stopped being “nice to have” and became a compliance baseline. By 2026, análise de vulnerabilidades em containers is viewed less as one technical task and more as a continuous, auditable process spanning developers, platform teams, security operations and leadership, all looking at similar metrics and risk dashboards instead of isolated vulnerability lists.
Core principles of container vulnerability analysis in 2026
At the core, modern container security rests on a few stable ideas: reduce the attack surface, know exactly what you ship, and keep that knowledge fresh as new CVEs appear. In practice, that means building minimal images, pinning versions, and never relying on “latest” tags. It also means generating and storing SBOMs for every image, so that later, when a new OpenSSL or glibc issue drops, your ferramentas para análise de vulnerabilidades em containers can answer in seconds which apps are affected. Another principle that matured by 2026 is treating containers as short‑lived but highly standardized units: instead of hardening each instance, you harden the image pattern and enforce policies at deployment and runtime.
A second key principle is to separate discovery from decision‑making. A scanner will always find “too many” findings; blindly trying to fix everything is unrealistic. Modern workflows use severity, exploitability context, runtime data and business impact to prioritize. For example, a critical CVE in a debug tool inside a non‑networked job container may rank lower than a medium issue in a public API image with internet‑facing endpoints. Successful teams wire scanners into CI/CD, registries and cluster admission, then define clear policies: which severities block a merge, which require waivers, and when compensating controls like network policies, PodSecurity or WAF rules are acceptable for a limited time while engineering works on an upgrade path.
SBOM, provenance and runtime context
Since 2024, SBOMs have become almost mandatory in regulated sectors, and by 2026 even startups treat them as standard practice. Instead of scanning the same image differently across tools, they generate one SBOM at build time, sign it, and let each plataforma de gestão de vulnerabilidades em containers ingest that document and correlate it with their CVE database. This reduces inconsistencies, speeds up rescans when new vulnerabilities are published, and makes it easier to prove to auditors that an image has not been tampered with. Provenance metadata from systems like Sigstore further reinforces trust by documenting who built the image, from which source, and under which policies.
Runtime context is the other half of the picture. An image might contain dozens of vulnerable libraries that are never loaded in memory or reachable from network entry points. Modern engines combine static scan results with runtime telemetry from Kubernetes or service meshes: which processes actually ran, which ports opened, which outbound domains were contacted. By 2026, the melhores ferramentas de segurança para containers kubernetes offer integrated views that tie pods, namespaces and services to specific image digests and vulnerability sets, boosting prioritization accuracy, and helping teams focus mitigation efforts where real exploitation paths exist, not just where theoretical weaknesses live on disk.
Tools and platforms for vulnerability analysis
The tool ecosystem has matured from standalone scanners into integrated pipelines. Teams still use a scanner de vulnerabilidades para imagens docker to parse OS packages and language dependencies, but the scanner is usually embedded: as a CI job, as a registry plugin or as an admission controller. Free and open‑source tools continue to dominate early adoption because they are easy to integrate and automate, but most medium and large organizations now layer commercial platforms on top to handle asset inventory, risk scoring, exception workflows and integrations with ticketing and SIEM systems. A typical stack combines build‑time scan, registry‑time enforcement and cluster‑time policy checks.
When people ask for ferramentas para análise de vulnerabilidades em containers in 2026, they often expect much more than “run this command on an image.” Modern platforms correlate container findings with host kernel posture, cloud misconfigurations and identity issues. Many also use machine learning to deduplicate repeated findings across thousands of workloads and highlight anomalies in how containers behave over time. Instead of dozens of disjoint dashboards, security and platform teams lean on a single plataforma de gestão de vulnerabilidades em containers, connected to cloud accounts, registries and Kubernetes clusters, offering a central view of risk posture, SLA breaches and remediation progress across multiple environments and business units.
Kubernetes‑aware security tooling
Kubernetes shifted the focus from individual containers to orchestrated workloads. The melhores ferramentas de segurança para containers kubernetes no longer restrict themselves to scanning static images; they inspect manifests, Helm charts and GitOps repositories, checking for risky configurations like privileged pods, hostPath mounts or missing resource limits. They then join that configuration intelligence with image vulnerability data and cluster runtime events, revealing, for example, that a vulnerable container also runs with cluster‑admin‑level service accounts. This combined context is crucial when deciding which findings deserve an emergency patch cycle versus a planned upgrade.
Another big step in 2026 is deep integration with the Kubernetes admission chain. Instead of passively reporting that some deployment uses an image with high‑severity CVEs, policy engines can actually stop the object from being created or updated, unless the change carries an explicit waiver label or references a formal risk acceptance ticket. This turns container vulnerability analysis into a hard gate when needed, not just background noise. To avoid blocking developers unexpectedly, more teams now run the same policies earlier, inside pull request checks, so that failures appear while code is still being written, accompanied by actionable guidance and links to internal standards.
Workflows and CI/CD integration
The real challenge is not picking tools, but designing workflows that people can live with. A sustainable pipeline treats security steps as first‑class citizens alongside tests and lint checks. In a modern setup, each commit triggers unit tests and a build, then an image is produced, its SBOM generated, signatures applied and multiple scanners executed. If any step fails, feedback is pushed to the pull request with clear explanations. After merging, the same image flows through staging and production, but its digest remains unchanged, guaranteeing that the artifact you scanned in CI is exactly what runs in the cluster. Drift is treated as an incident, not a minor glitch.
When teams ask como implementar pipeline de segurança e scan de imagens em CI/CD, the answer in 2026 tends to follow a similar pattern: define policies in code, run scans as close to the developer as possible, and use the CI system as the enforcement engine. That means codifying severity thresholds, approved base images and signing requirements in version‑controlled configuration. The CI/CD platform reads those rules, calls scanners and policy engines, and only promotes artifacts that comply or carry an approved exception. Over time, organizations refine thresholds, add language‑specific SCA steps, integrate with container registries and even automatically open tickets with suggested upgrades for recurring vulnerable components.
Metrics and KPIs that matter
Vulnerability analysis without metrics quickly devolves into fire drills. In 2026, high‑performing teams track a mix of quantitative and qualitative indicators. They monitor the number of critical and high‑severity findings per image and per environment, but also pay close attention to mean time to remediate and mean time to detect once new CVEs appear. Freshness is key: an image with no known vulnerabilities but built a year ago is inherently risky, because new flaws may have surfaced since. Many teams define a maximum image age policy, forcing regular rebuilds even when application code doesn’t change.
Another important metric family revolves around coverage and policy adherence. Teams want to know what percentage of images in use have SBOMs, signatures and at least one recent scan; how many workloads run with privileged flags; and how many deployments are blocked by admission policies versus slipped through via emergency exceptions. On the organizational side, they measure how often developers see security feedback during normal work, not just during quarterly audits. Mature companies move away from pure “vulnerability counts” and adopt risk scores that incorporate runtime exposure, network reachability, business criticality and presence of compensating controls like strict NetworkPolicies or mTLS.
Common misconceptions about container vulnerability analysis
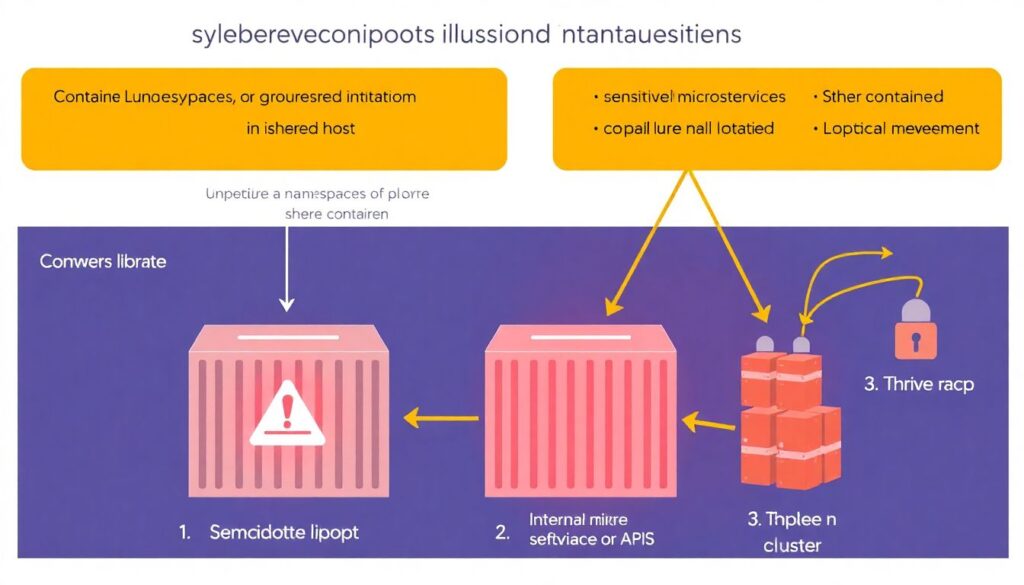
A widespread misconception is that containers are “isolated enough” to ignore patching. Namespaces and cgroups limit blast radius, but a vulnerable library in one container can still be abused to access data, call internal services or pivot inside a cluster. Another naive belief is that using official or vendor‑supplied images guarantees safety. In reality, those images often bundle more tools than necessary and may lag behind distribution security updates. Treating them as untouchable black boxes contradicts basic security hygiene; you should still scan them, trim them and track their vulnerabilities like any other component in your stack.
A second misconception is equating “we run a scanner” with “we have a robust process.” Running a one‑off scan before release has little value if no one triages the results, no owner is assigned and no due dates exist. Teams sometimes assume that a magic scanner will perfectly classify severity and exploitability, when in practice, someone needs to connect findings with architecture and business priorities. Finally, some organizations think that moving to serverless or managed Kubernetes makes container vulnerabilities “someone else’s problem.” Cloud providers secure the control plane and some base layers, but whatever you package in the image — from frameworks to custom binaries — remains your responsibility.
Modern trends and what’s new in 2026
By 2026, vulnerability analysis is deeply intertwined with software supply chain security. Instead of treating containers as the first step of analysis, teams begin at the repository: signed commits, dependency pinning, reproducible builds, and continuous SBOM generation. This upstream discipline dramatically reduces the noise downstream in images and clusters. Another strong trend is policy‑as‑code, using frameworks that allow security and platform engineers to express rules in declarative languages, version them and test them just like regular software. This reduces friction because developers can see exactly which policies will apply and can propose changes via pull requests.
Automation is also getting smarter. Platforms ingest data from multiple scanners, cloud security tools and runtime monitors, then automatically group related findings, suppress known false positives, and highlight anomalies like a new image suddenly talking to unfamiliar external domains. LLM‑powered assistants help developers understand vulnerability reports, propose upgrade paths and even generate patches or configuration changes. While this automation cannot replace human judgment, it shortens feedback loops significantly. In regulated industries, experimental predictive models try to estimate which images or services are likely to accumulate critical issues soon, enabling proactive hardening campaigns before the situation becomes urgent.
Practical implementation examples
Consider a mid‑size SaaS company migrating from a monolithic VM‑based setup to Kubernetes. Initially, they only used a basic scanner de vulnerabilidades para imagens docker right before deploying, which flooded them with findings and frustrated developers. Over two years, they redesigned the workflow: SBOM generation at build time, signed images in a private registry, admission policies blocking critical CVEs, and a consolidated dashboard where tech leads review risk weekly. They also linked their vulnerability platform with their incident management tool so that every high‑severity finding in production creates a tracked task with clear ownership and SLA, turning a chaotic backlog into a manageable stream of work.
In a larger enterprise, the journey often starts from compliance pressure. A bank, for instance, might have hundreds of microservices across multiple clusters and cloud providers. They typically adopt a central plataforma de gestão de vulnerabilidades em containers that connects to all registries, CI systems and clusters. Each business unit keeps autonomy over tech stacks, but everyone shares the same risk scoring model and escalation rules. Security teams define global guardrails, while local platform teams tune policies to their context. Over time, metrics show decreasing mean time to remediate, fewer unscanned images in production and less friction between security and engineering, because expectations and workflows are clear and enforced automatically rather than negotiated manually each release.