Serverless security looks deceptively simple: you write a small function, deploy, and let the cloud provider handle the rest. The catch is that “the rest” hides a pile of shared responsibility details, and attackers absolutely know where those gaps are. In this article we’ll walk through real‑world risks de segurança em ambientes serverless, what actually goes wrong in production, and how to plug those holes with concrete habits, configs and tools you can apply this week, not “someday later” when you refactor everything.
Why serverless security feels different (and bites faster)
In a classic VM or container setup, you at least see your servers, patches and daemons. In function‑as‑a‑service, security issues are often configuration mistakes and glue‑code bugs between services, rather than obvious OS problems. That’s why segurança em serverless melhores práticas começam com entender o modelo de responsabilidade compartilhada: the provider defends the infrastructure; you own identity, data handling, code and integration with other managed services. Ignoring that line is how production incidents quietly start.
Serverless environments also make it trivial to scale damage. A single vulnerable Lambda or Cloud Function exposed by API Gateway can be triggered tens of thousands of times per minute. I’ve seen billing alerts fire because a poorly rate‑limited endpoint was hit by a dumb bot and turned into an accidental denial‑of‑wallet within hours. When you think about como proteger aplicações serverless na nuvem, you need to consider not only confidentiality and integrity, but also cost‑amplified attacks that abuse automatic scaling.
Specific risks you don’t see in “traditional” apps
One of the most under‑estimated riscos de segurança em ambientes serverless is over‑permissive IAM roles. Teams often start with “just give it AdministratorAccess so it works in dev” and somehow that role ends up in production. From there, any injection bug in your function can become full account compromise: reading all S3 buckets, spinning up crypto‑miners, or exfiltrating secrets from Parameter Store. The code vulnerability might be small, but the blast radius is enormous because the role can do everything.
Another common trap is event injection. Since serverless thrives on triggers (SQS messages, SNS, Kafka, webhooks), the function often trusts the shape and content of events too much. I worked with a team whose function parsed JSON from a third‑party webhook and directly mapped a field into a dynamic database query; one malformed payload later, they had a privilege escalation in their own system. They had never treated event payloads as untrusted input, even though they crossed trust boundaries like any other external request.
Technical deep dive: IAM and least privilege
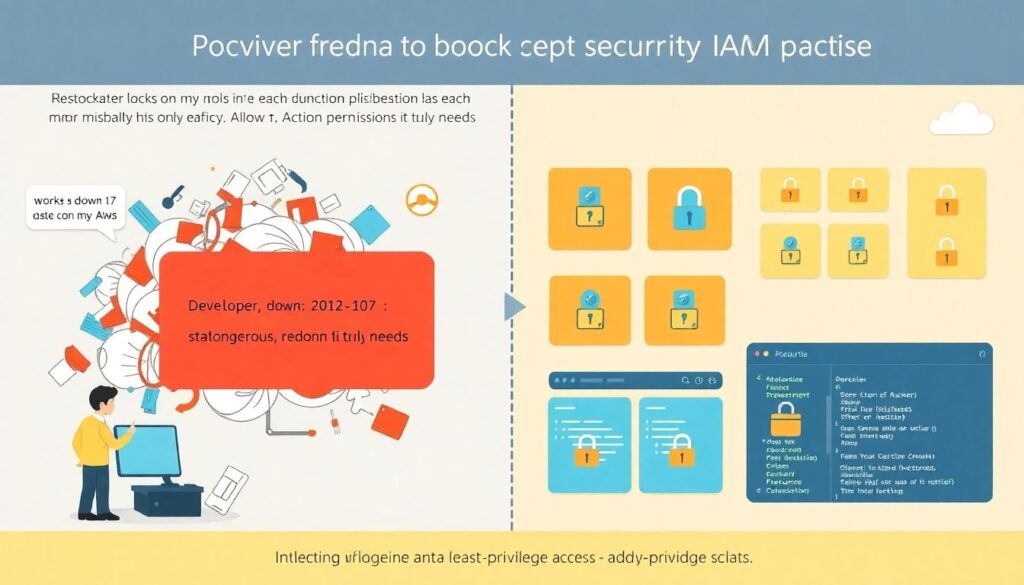
A practical first step is to lock down roles so each function can do only what it really needs. For example, instead of this “works on my machine” policy that I still see in audits:
“`json
{
“Version”: “2012-10-17”,
“Statement”: [{
“Effect”: “Allow”,
“Action”: “*”,
“Resource”: “*”
}]
}
“`
You want something closer to this, even if it feels annoyingly specific at first:
“`json
{
“Version”: “2012-10-17”,
“Statement”: [{
“Effect”: “Allow”,
“Action”: [
“dynamodb:PutItem”,
“dynamodb:GetItem”
],
“Resource”: “arn:aws:dynamodb:us-east-1:123456789012:table/orders”
}]
}
“`
On real projects, we usually generate these policies from access‑analysis or IaC scans. The payoff is immediate: a bug in one function no longer translates into a full account takeover. It also makes threat modeling easier, because you can reason about “what’s the worst damage this role can cause” and sleep a bit better.
Inputs, dependencies and secrets: the everyday attack surface
When we talk about segurança em serverless melhores práticas in code, three boring‑sounding topics are where incidents actually happen: input validation, dependency hygiene and secret management. Every trigger—HTTP, queue, cron, storage event—should go through a consistent validation layer with schema checks and size limits. This isn’t theoretical; I’ve seen a single oversized message (80 MB CSV) cause repeated cold starts and spike latency, then masking a simple denial‑of‑service caused purely by payload size.
Dependencies are another quiet problem. Serverless functions often bundle a mini‑universe of libraries because “it’s small anyway.” Over time, you end up with dozens of transitive packages, some unmaintained for years. In one assessment, more than 60% of a function’s ZIP size was third‑party code; among those packages we found a known RCE vulnerability that was already being exploited in the wild. Automated SCA (Software Composition Analysis) in CI isn’t optional here; you want functions to fail builds when a high‑severity CVE appears, not after your next quarterly review.
Monitoring, logging and observability that actually help
Many teams add logs “for debugging” and stop there, but monitoramento e logs em arquitetura serverless are your early‑warning system for security incidents, not just for chasing 500 errors. The practical goal is simple: from a single dashboard you should be able to answer “who called this function, with what, and what did it touch” within a few minutes. That’s almost impossible if logs are ad‑hoc printlns with random formats and no correlation IDs. You’ll end up reading walls of text at 3 AM during an incident.
Here’s a minimal logging pattern you can wire into a wrapper or middleware:
“`js
exports.handler = async (event, context) => {
const requestId = context.awsRequestId;
console.log(JSON.stringify({
level: “info”,
msg: “request_received”,
requestId,
sourceIp: event.requestContext?.identity?.sourceIp,
userArn: event.requestContext?.identity?.userArn
}));
// business logic here
};
“`
With a consistent JSON structure and a correlation field, ferramentas de observabilidade para serverless like Datadog, New Relic, Lumigo or AWS X‑Ray can build traces and alert on suspicious patterns: spikes in 4xx/5xx, weird geographies, or sudden growth in payload size. Without that structure, security‑relevant anomalies just disappear into noise.
Key best practices you can roll out this month

Instead of a giant checklist, here’s a short, practical plan that I’ve seen work in real teams moving fast:
1. Lock down IAM: audit existing roles, remove wildcards, and split shared roles into function‑specific ones.
2. Standardize input validation: build or adopt a tiny validation layer and use it for every trigger type.
3. Centralize secrets: migrate environment variables with sensitive data into KMS, SSM or Secret Manager.
4. Implement structured logging: JSON logs with correlation IDs and user context where possible.
5. Add basic anomaly alerts: rate, error‑rate and cost alerts per function or per API route.
You don’t need a huge security program to start; these five items alone significantly cut risk. Each one tackles a different angle—permissions, data, secrets, visibility and detection—so you’re not betting everything on a single control.
Observability tools with a security lens
A lot of teams ask for “ferramentas de observabilidade para serverless” and then deploy whatever their cloud account suggests by default. The trick is to configure them for security, not just performance. For instance, in AWS you can connect CloudTrail, CloudWatch Logs, X‑Ray and GuardDuty to paint one coherent picture: who changed which function, what events triggered it, what downstream services it touched and whether any of that matches known malicious behavior. Out of the box, these tools are noisy, but with a couple of days of tuning you get real signal.
In practice, what works well is layering: native cloud logs for low‑level events, a vendor or open‑source platform for cross‑service correlation, and simple, explicit runbooks for common alerts. If your dashboard says “sudden spike in invocations from a new country plus increased DynamoDB throttling,” the on‑call person should know exactly which steps to run: block suspicious IPs, add extra rate limits, and capture samples for later forensics. Observability without these concrete playbooks tends to devolve into “we have beautiful graphs, but nobody knows what to do.”
Bringing it all together in real projects
If you’re wondering como proteger aplicações serverless na nuvem without stopping delivery, start small but be relentless about consistency. Pick one service boundary—say, your public API—and make it your “secure by default” playground: least‑privilege roles, validated inputs, structured logs, alerts and monthly dependency scans. Once that slice feels boringly stable, copy the pattern into other parts of your architecture. Over a few sprints, your default serverless template becomes secure by habit, not by exception or heroics.
The main mindset shift is to treat serverless security as guardrails around fast iteration, not gatekeeping. When your templates, CI checks and observability baselines are wired in, developers can spin up new functions quickly without re‑negotiating every control. That’s how you get both speed and safety: small pieces, locked‑down permissions, rich telemetry and automated checks catching regressions before attackers do.