
To map and reduce the attack surface in cloud microservice architectures, first inventory every service and communication path, then systematically remove or lock down unnecessary entry points. Apply least privilege, segment networks with zero trust, harden runtimes, and automate detection. Start small with critical services and iterate continuously.
Quick Security Priorities for Microservice Attack Surface
- Maintain an up-to-date inventory of all services, APIs, and ingress paths.
- Limit public exposure to a few controlled entry points with strong authentication.
- Enforce least-privilege IAM for services, users, and CI/CD pipelines.
- Apply network segmentation and zero trust between microservices.
- Harden containers, runtimes, and hosts with baselines and scanning.
- Continuously monitor with logs, metrics, traces, and security alerts.
- Regularly review architecture to remove unused components and permissions.
Inventorying Services and Communication Flows
This approach suits teams already running multiple services in Kubernetes or managed container platforms and wanting practical segurança em microserviços na nuvem without a full redesign. It is less useful if you are still at early prototype stage with a single service and no persistent data.
Goal of this phase
Create a reliable map of all microservices, APIs, data stores, and communication flows, so you know exactly what needs protection and where your attack surface actually is.
Recommended tools and data sources
- Cloud provider inventory: AWS Config, Azure Resource Graph, GCP Asset Inventory.
- Kubernetes: kubectl, cluster API discovery, ingress and service manifests.
- Service mesh or gateway: Istio, Linkerd, NGINX Ingress, API Gateway route definitions.
- Observability: OpenTelemetry traces, application logs, network flow logs, eBPF-based tools.
- CI/CD and registries: pipeline definitions, container registries, serverless configuration.
Step-by-step actions for reliable mapping
-
List all deployed workloads
Query your cloud accounts and clusters for every running workload: deployments, jobs, serverless functions, databases, queues, and managed services.
- Export results to a spreadsheet or configuration repository.
- Include environment (dev, staging, production) and region for each item.
-
Identify all ingress and egress points
Locate every internet-facing and cross-network entry and exit: load balancers, API gateways, ingress controllers, VPNs, bastions, and public buckets or queues.
- Flag each entry as public, partner, or internal-only.
- Record associated DNS names and paths.
-
Map service-to-service calls
Use traces, mesh telemetry, or application logs to capture who calls whom, over which protocol and port.
- Focus on paths into sensitive services such as payments or identity.
- Note whether calls are authenticated, encrypted, and authorized.
-
Document data flows and data stores
For each service, document what data it stores or accesses and where, including relational databases, NoSQL, object storage, caches, and message queues.
- Tag data as public, internal, or sensitive (for example personal or financial).
- Mark which stores are internet accessible or cross-account accessible.
-
Review identity and access points
Enumerate all IAM roles, service accounts, API keys, and OAuth clients tied to your microservices.
- Identify high-privilege roles spanning multiple services or environments.
- Note where secrets are stored and how they are rotated.
Measurable outcome for the inventory
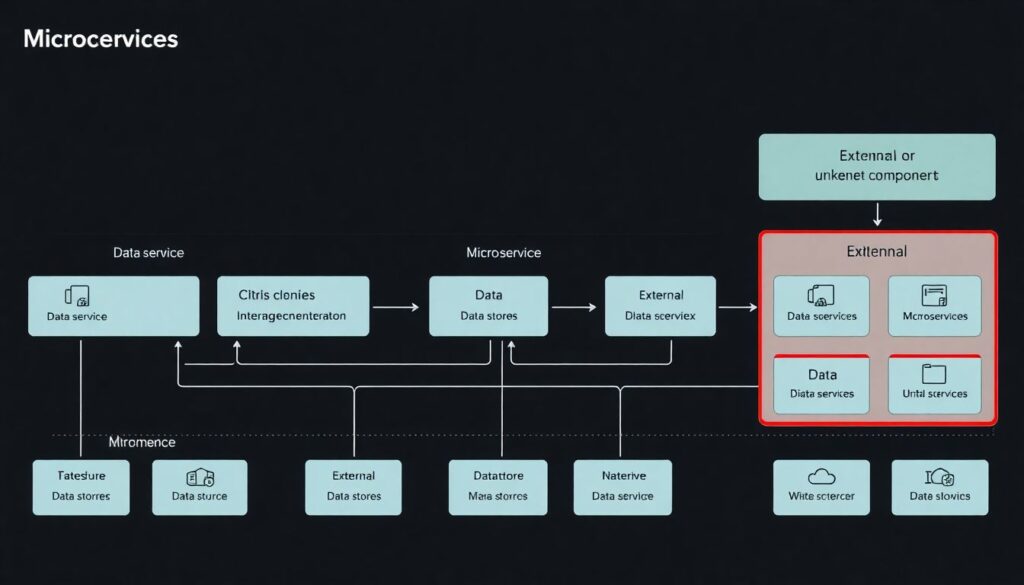
- Single living document (or repository) listing all services, data stores, and endpoints.
- Clear diagram of main communication flows between microservices and the internet.
- List of unknown or unmanaged components discovered during mapping.
Threat Modeling for Cloud-Native Components
What you need before starting
- A reasonably current inventory of services, APIs, data stores, and communication flows.
- Architecture diagrams at a level that shows microservices, gateways, and data paths.
- Access to cloud IAM policies, Kubernetes manifests, and gateway configuration.
- At least one person who understands business impact and data classification.
Helpful tools and techniques
- Diagramming: draw.io, Lucidchart, or cloud provider architecture tools.
- Threat modeling frameworks: STRIDE, attack trees, or simple what-if scenarios.
- Cloud-native analyzers: IAM policy analyzers, Kubernetes security scanners.
- Security runbooks: response procedures for common microservice incidents.
Practical approach tailored to microservices in cloud
-
Identify critical assets and trust boundaries
Mark services handling sensitive data or critical operations and the boundaries between users, API gateways, microservices, and data stores.
-
Enumerate realistic attacker paths
Using como reduzir superfície de ataque em arquitetura de microserviços as your guiding question, list ways an attacker could enter and move: via exposed APIs, compromised credentials, misconfigured IAM, or vulnerable containers.
-
Score impact and likelihood
For each path, rate potential business impact and likelihood. Prioritize what is both impactful and plausible in your environment.
-
Derive concrete controls
Translate threats into specific controls such as tighter IAM, mTLS, stricter network policies, and policy-as-code checks in CI/CD.
Output should be a short list of top threat scenarios with mapped controls and owners, aligned with melhores práticas de segurança para microserviços em cloud.
Minimizing Exposed Interfaces and APIs
This phase directly removes unnecessary attack paths and tightens the controls on those that must remain for business reasons.
-
Consolidate and standardize ingress points
Reduce multiple ad-hoc public endpoints to a small set of managed ingress controllers or API gateways with consistent policies.
- Terminate TLS only at trusted gateways with modern ciphers and certificates.
- Apply rate limiting, IP filtering, and WAF rules at the edge.
-
Restrict which services are internet-facing
Review every service exposed via load balancer, API gateway, or public IP, and move non-essential ones behind private networking or internal gateways.
- Mark services as public, partner-only, or internal-only in configuration.
- Use private load balancers and private DNS for internal services.
-
Enforce strong authentication and authorization at the edge
Require authenticated, authorized access for all non-public APIs using OAuth2, OpenID Connect, or mTLS, integrated with your identity provider.
- Prefer token-based auth with short lifetimes and audience restrictions.
- Offload auth to API gateway or service mesh where possible.
-
Reduce API surface area and methods
Audit public and partner APIs, deprecate unused endpoints, and limit methods or query parameters that are not strictly required for business flows.
- Remove debug or admin endpoints from internet-facing interfaces.
- Document required schemas and reject unexpected fields by default.
-
Lock down management and admin interfaces
Ensure orchestrator dashboards, message brokers, databases, and admin UIs are never directly exposed to the internet.
- Require VPN, zero trust access, or bastion hosts for operational access.
- Enable MFA for all admin and break-glass accounts.
-
Harden TLS, certificates, and service identities
Use consistent TLS policies between microservices, ideally managed by a service mesh with automatic certificate rotation and mutual TLS.
- Disable insecure protocols and weak ciphers.
- Monitor certificate expiry and automate renewals.
-
Validate inputs and handle errors carefully
Apply strict input validation at API boundaries and avoid returning detailed stack traces or internal identifiers in errors.
- Centralize validation logic and reuse schemas where possible.
- Log detailed errors internally while returning generic messages to clients.
Fast-Track Mode: Minimum Viable Hardening
- Route all external traffic through a single hardened API gateway or ingress.
- Restrict internet exposure to the gateway and one or two essential public services.
- Require authentication on every non-public endpoint, using your existing identity provider.
- Disable or firewall all admin and debug UIs from the internet immediately.
- Schedule a short monthly review to remove obsolete APIs and endpoints.
Network Segmentation and Zero Trust for Microservices
This section focuses on verifying that segmentation and zero trust policies work as intended, not only that they are defined.
Operational verification checklist
- Each microservice has an explicit network policy or security group definition allowing only necessary inbound and outbound traffic.
- Default behavior for new services is deny-by-default for network traffic until policies are explicitly added.
- Service-to-service traffic is encrypted in transit, preferably using mTLS enforced by a service mesh or sidecar pattern.
- No direct database or message broker access is allowed from the internet or from unrelated services.
- Production, staging, and development environments are isolated at the network and IAM levels, with no direct lateral movement possible.
- Jump hosts, VPNs, and zero trust access tools are the only entry points for operational access to internal services.
- Network flow logs and service mesh telemetry show that unexpected or unused paths are rare and investigated.
- Security tests and chaos experiments include attempts to call services from unauthorized networks or namespaces.
- Segmentation rules are stored as code (for example Kubernetes network policies, firewall-as-code) with code review and change history.
- Emergency break-glass access paths are defined, tested, and tightly governed.
Runtime Hardening: Containers, Runtimes and Hosts

Reducing the attack surface at runtime requires avoiding common configuration and operational mistakes that attackers routinely exploit.
Frequent pitfalls to avoid
- Running containers as root or with excessive capabilities, making privilege escalation easier.
- Using unpinned or unscanned images from public registries without provenance or SBOM information.
- Embedding secrets, tokens, or credentials in images, environment variables, or code repositories.
- Granting containers hostPath mounts, privileged mode, or access to the Docker or container runtime socket.
- Ignoring Kubernetes Pod Security Standards or equivalent hardening baselines for your orchestrator.
- Failing to apply kernel and host OS patches that mitigate known container escape techniques.
- Overlooking runtime anomaly detection, such as unexpected process execution or file system access inside containers.
- Sharing nodes between workloads of vastly different sensitivity without adequate isolation.
- Allowing CI/CD systems overly broad permissions to deploy, modify, or read secrets in production.
- Relying only on perimeter defenses and ignoring host-level and runtime security checks.
Automated Detection and Continuous Reduction
After initial hardening, the key is to detect drift and new exposures automatically and react quickly.
Alternative implementation patterns
-
Security platform integrated with observability
Use a cloud-native security platform that ingests logs, metrics, and traces, correlates them with configuration data, and alerts on suspicious behavior. This suits teams with strong observability already in place and limited dedicated security staff.
-
Policy-as-code and CI/CD enforcement
Embed security checks into CI/CD using tools that evaluate IaC, Kubernetes manifests, and policies before deployment. This is ideal if you have disciplined pipelines and want to make regressions hard to ship.
-
Service mesh and eBPF-based runtime visibility
Combine a service mesh for mTLS and traffic policy with eBPF tools that monitor system calls and network flows. This approach is powerful for advanced teams needing deep runtime insight, but introduces operational complexity.
-
External expert guidance and periodic reviews
Engage a serviço de consultoria em segurança de microserviços na nuvem to run regular reviews, threat modeling sessions, and penetration tests. This works best if you want independent validation and tailored guidance on ferramentas de segurança para microserviços em cloud.
Practical Clarifications and Implementation Traps
How often should I update my microservice attack surface map?
Update the map whenever you introduce new services, major features, or environments, and run at least a quarterly review. Automate discovery where possible so your inventory stays aligned with reality.
Do I need a service mesh to implement zero trust in microservices?
A service mesh simplifies mTLS and fine-grained policies but is not mandatory. You can start with strong IAM, network policies, and gateway-level controls, then introduce a mesh when the operational overhead is justified.
What is the safest way to start reducing public endpoints?
Begin by identifying obviously unnecessary or low-traffic public endpoints and migrate them behind an internal gateway or private networking. Monitor impact closely and communicate changes to dependent teams and partners before removal.
How can intermediate teams avoid breaking apps while tightening network policies?
First deploy policies in audit or permissive mode to observe what would be blocked. Use logs to adjust rules, then progressively enforce them in non-production before rolling into production with clear rollback plans.
Where should I focus first: IAM, network, or runtime hardening?
For most environments, start with reducing public exposure and tightening IAM on critical services and data stores. Then address basic network segmentation, followed by runtime hardening and automated detection.
Are commercial tools required to secure microservices in cloud?
No, but the right tools can accelerate work and reduce mistakes. Start with native cloud controls, open-source scanners, and observability, then consider commercial platforms if scale and complexity demand them.
How does this approach align with melhores práticas de segurança para microserviços em cloud?
It follows common best practices: least privilege, minimal exposure, defense in depth, automation, and continuous review. The steps are designed to be incremental and safe for intermediate teams operating in production.